
Giới thiệu
Xin chào các bạn, với sự bùng nổ từ sau cơn “địa chấn” chatGPT. Các công ty công nghệ bắt đầu “điên cuồng” đổ tiền và nguồn lực vào các ứng dụng nền tảng của họ, thường sẽ đấu nối với OpenAI hoặc Azure AI gần đây. Với mong muốn có thể đưa AI vào danh mục chức năng của sản phẩm hoặc dịch vụ mình cung cấp cho khách hàng (trending mà).
LangChain là gì?
Để đáp ứng nhu cầu bùng nổ về việc phát triển các ứng dụng trên LLM, một đội ngũ được dẫn Harrison Chase trên thế giới đã phát triển ra một công cụ mang tên LangChain. LangChain được định nghĩa là một framework, được xây dựng chính trên ngôn ngữ Python và Javascript.
LangChain được xây dựng dựa trên định nghĩa như là một phương thức (framework) giúp các nhà phát triển phần mềm tạo ra các công cụ từ LLM một cách đơn giản và hiệu quả. Với các tiếp cận là coi LLM là nơi xử lý ngôn ngữ từ người dùng, application sẽ là nơi điều khiển việc nhận truy vấn từ người dùng đó và xử lý các tác vụ liên quan tuỳ thuộc vào đề bài. Ví dụ: đọc dữ liệu vào bộ nhớ, truy vấn dữ liệu đó, trích xuất dữ liệu báo cáo v.v
Một số định nghĩa trong LangChain
| Thuật ngữ | Định nghĩa |
|---|---|
| Model I/O | Thành phần chính của một ứng dụng LLM. Cung cấp một số chức năng để tương tác với các LLMs (Ví dụ: Azure hay OpenAI) |
| Data Connection | Các ứng dụng LLM thường sẽ cần bộ dữ liệu nội bộ hoặc các dữ liệu thông qua API/Internet. Module này sẽ giúp bạn kết nối LangChain vào các CSDL. |
| Chains | Để sử dụng LLM, bạn sẽ cần phải gọi các APIs hay gRPC trực tiếp tới model. Nhưng sau đó sẽ cần thao tác các công việc khác. Module này được thiết kế để hoàn thành một chuỗi thao tác đó giúp bạn. |
| Memory | Đúng với cái tên của nó, module này sẽ giúp ứng dụng LLM có nơi lưu trữ dữ liệu cho nó. Có thể dữ liệu ngắn hạn hoặc dài hạn tuỳ theo cách bạn thiết kế. |
| Agents | Một số ứng dụng LLM sẽ khá phức tạp. Ví dụ người dùng đưa vào một truy vấn, và đòi hỏi ứng dụng phải tự hiểu được người dùng mong muốn gì. Ví dụ như truy xuất dữ liệu và tạo chart. |
| Callbacks | Module này giúp bạn có thể nhận kết quả ở các bước trong LangChain. Chủ yếu dùng cho Logging, Debugging hoặc Streaming data (như chatGPT, đoạn text sẽ xuất hiện từ từ). |
Lưu ý: bảng định nghĩa này có thể không còn chính xác trong tương lai. Vì LangChain vẫn còn trong giai đoạn phát triển. Bản thân người viết cũng cần phải cập nhật lại, vì cách đây 03 ngày trước, bảng định nghĩa vẫn còn khác hiện tại.
Cách thức hoạt động
Để hiểu rõ hơn cách thức hoạt động cho ứng dụng, các bạn có thể xem mô hình sequence-diagram dưới đây.
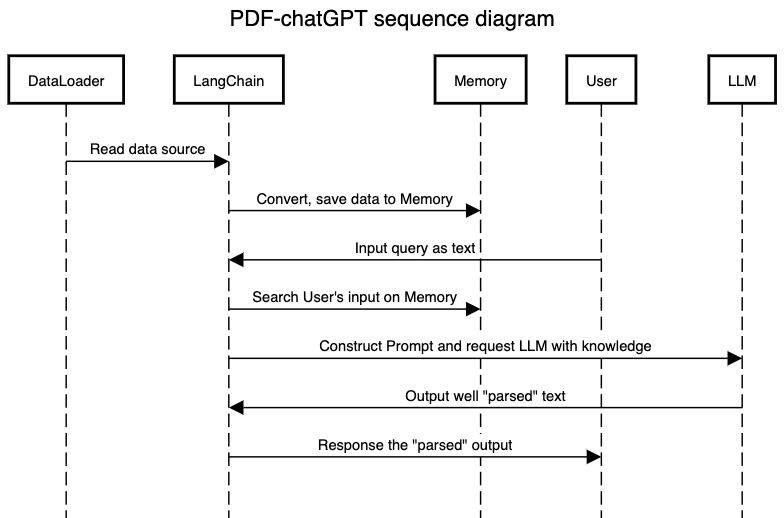
Thực hành
Chuẩn bị
Để phục vụ cho ứng dụng, bạn sẽ cần phải cài đặt các bộ thư viện dưới đây.
pip install langchain==v0.0.204 streamlit==1.24.0 streamlit-chat==0.1.0 python-dotenv==1.0.0 openai==0.27.7 PyMuPDF==1.22.5 faiss-cpu tiktoken==0.4.0Note: có một số bạn phản hồi cho mình về trình trạng lỗi thư viện. Mình đã sửa nó thành đúng version lúc viết bài này. Hoặc bạn có thể chạy pip install -r requirements.txt, nếu bạn đã pull code từ github về.
Sau đó, tạo một file pdf_chatgpt.py và copy đoạn code dưới đây.
# LangChain Dependencies
from langchain import ConversationChain, PromptTemplate
from langchain.document_loaders import PyMuPDFLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.memory import VectorStoreRetrieverMemory
from langchain.vectorstores import Chroma
#For Streamlit to build UI
from streamlit_chat import message
import streamlit as st
#Load Configuration
import os
from dotenv import load_dotenv
# Bootstrap
load_dotenv()
OPENAI_API_KEY = os.environ.get('OPENAI_API_KEY')Ở đoạn code trên, chúng ta import các bộ thư viện của LangChain, và Streamlit.io, đồng thời chúng ta sẽ load OpenAI Api key vào trong ứng dụng. Như thế là xong giai đoạn chuẩn bị.
Xây dựng “Backend”
Data-Connection
Tiếp theo, các bạn paste đoạn code sau.
# Data loader. In this tutorial, we use PDF loader to load PDF
loader = PyMuPDFLoader("./pdf_library/JOODB.pdf")
docs = loader.load()Đoạn code sử dụng thư viện PyMuPDFLoader để “đọc” nội dung trong file PDF. Mỗi trang trong pdf sẽ thành một Document, vì vậy đoạn docs = loader.load() sẽ bao gồm danh sách các Document được phân ra từ PDF.
Memory
Tiếp theo, chúng ta sẽ khởi tạo Embedding và cơ sở dữ liệu Chroma.
# Embedding does convert text to vector
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
# We create mem(Chroma) for the application.
chroma_mem = Chroma.from_documents(documents=docs, embedding_function=embeddings)- embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY) khởi tạo OpenAI Embedding. Các thư viện Embedding có nhiệm vụ chuyển đổi nội dung thành một dãy số (Vector) và lưu trữ vào các cơ sở dữ liệu phù hợp (như Chroma trong đoạn code). Khi thực hiện tìm kiếm, các thư viện Embedding sẽ tiến hành chuyển đổi truy vấn sang vector và thực hiện search tren dữ liệu lưu trữ trước đó. Kết quả gần nhất sẽ được trả về (Cosine similarity).
- chroma_mem = Chroma.from_documents(documents=docs, embedding_function=embeddings) khởi tạo một instance Chroma kèm theo, đồng thời khỏi tạo một bộ dữ liệu dựa trên docs chúng ta đã parse từ trước đó. Như đã miêu tả ở trên, LangChain sẽ cần thư viện Embedding đưa dữ liệu dạng text sang vector để lưu trữ vào csdl.
#We create Index, which indexes data on Chroma
retriever = chroma_mem.as_retriever(search_kwargs=dict(k=5))
#We create a VectorStore (Chroma Wrapper)
memory = VectorStoreRetrieverMemory(retriever=retriever)- Ở đoạn retriever = chroma_mem.as_retriever(search_kwargs=dict(k=5)), LangChain sẽ cần một một bộ phương thức để truy cập dữ liệu. as_retriever() sẽ chuyển đổi csdl Chroma thành một retriever, với k=5 sẽ báo rằng chúng mặc định sẽ lấy 05 kết quả gần nhất với kết quả tìm kiếm.
- VectorStoreRetrieverMemory() là một Class trong LangChain được thiết kế để quy chuẩn hoá cách thức lấy dữ liệu từ bộ nhớ. Ở đây chúng ta khởi tạo một object của Class này với tên memory. Memory này sẽ được dùng trong mục tiếp theo.
Model I/O
Ở phần này chúng ta sẽ tiếp tục khởi tạo LLM và truyền các đối tượng chúng ta đã khởi tạo trước đó để hoàn thành một LangChain hoàn chỉnh.
# Template
_DEFAULT_TEMPLATE = """The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Relevant pieces of previous conversation:
{history}
(You do not need to use these pieces of information if not relevant)
Current conversation:
Human: {input}
AI:"""
PROMPT = PromptTemplate(
input_variables=["history", "input"], template=_DEFAULT_TEMPLATE
)
llm = OpenAI(temperature=0.7, openai_api_key=OPENAI_API_KEY) # Can be any valid LLM
- _DEFAULT_TEMPLATE… là một chuỗi text, đoạn text này quan trọng đối với các GenerativeAI, đặc biệt là đối với GenerativeAI từ LLM. Ở đây chúng ta cho AI biết, nó cần phải đóng vai gì (một con bot hỗ trợ thông tin và thân thiện), và có những hạn chế gì (nếu không biết thì không được phép trả lời). Đồng thời, chúng ta cũng cung cấp dữ liệu trước đó (nằm trong {history}) để nó có thể trả lời dựa trên dữ liệu đó (ở đây là nội dung trong file PDF).
- PROMPT = PromptTemplate() chúng ta sẽ khởi tạo một object thuộc về PromptTemplate. PROMPT sẽ nhận history và input như placeholder để gắn các dữ liệu vào. Input là câu hỏi, và history là dữ liệu từ PDF đối với ứng dụng của chúng ta.
- llm = OpenAI… Chúng sẽ khởi tạo LLM model từ OpenAI’s API. Các bạn cần phải có OPEN_API_KEY được lấy từ tài khoản OpenAI của các bạn nhé.
Chains
conversation_with_summary = ConversationChain(
llm=llm,
prompt=PROMPT,
# We set a very low max_token_limit for the purposes of testing.
memory=memory,
verbose=True
)conversation_with_summary = ConversationChain() chúng ta sẽ khởi tạo một trong các Chain có sẵn của LangChain: ConversationChain. Đóng vai trò như một bộ Chain phục vụ cho việc hỏi và đáp giữa user và ứng dụng. Ứng dụng lúc này được đóng vai là một con bot phục vụ. Chúng ta sẽ cung cấp các object liên quan cho Chain như đoạn code trên.
Kết nối “Frontend”
Để tạo ra một giao diện chat trên browser từ đầu thì cũng đòi hỏi khá nhiều thời gian và công sức. Rất may chúng ta có thể sử dụng Streamlit để nhanh chóng dựng một giao diện giữa người dùng và con AI. Vì bài viết chỉ tập trung giải thích về LangChain và demo cách tạo ứng dụng nên mình sẽ không bàn nhiều về Streamlit nhé.
st.header("PDF-chatGPT")
if 'generated' not in st.session_state:
st.session_state['generated'] = []
if 'past' not in st.session_state:
st.session_state['past'] = []
def get_text():
input_text = st.text_input("You: ", "Hello, how are you?", key="input")
return input_text
user_input = get_text()
if user_input:
output = conversation_with_summary.predict(input=user_input)
st.session_state.past.append(user_input)
st.session_state.generated.append(output)
if st.session_state['generated']:
for i in range(len(st.session_state['generated']) - 1, -1, -1):
message(st.session_state["generated"][i], key=str(i))
message(st.session_state['past'][i], is_user=True, key=str(i) + '_user')
Kết quả
Chúng ta sẽ chạy đoạn command dưới đây trên terminal hoặc trên IDE mà bạn đang sử dụng.
streamlit run pdf_chatgpt.pyBạn sẽ cần một chút thời gian để ứng dụng khởi tạo và chạy trên browser. Sau khi ứng dụng được chạy, bạn có thể bắt đầu hỏi con AI. Như đoạn nội dung bên dưới, đoạn khởi tạo chúng ta sẽ luôn “Hello, how are you?” trước với con AI. Sau đó mình đã đặt câu hỏi “JOODB là cái gì” thì do con AI do đã được học từ file PDF JOODB.pdf, nó đã có thể trả lời được nội dung đó.
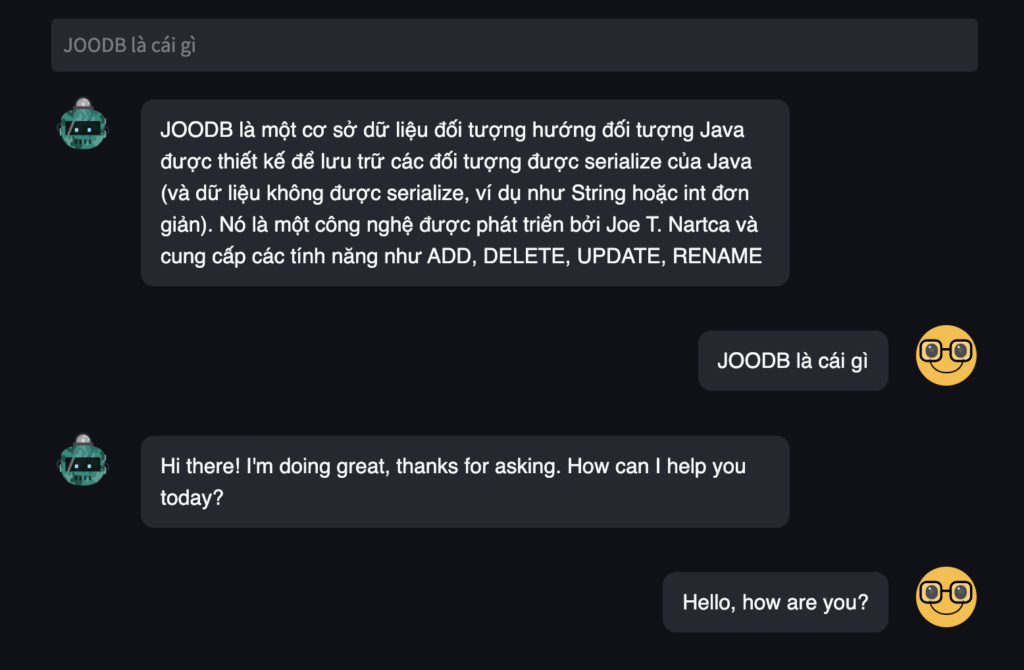
Để chứng thực điều đó, mình cũng đã sử dụng chatGPT để hỏi xem nó có biết JOODB là cái gì không? Và câu trả lời không nằm ngoài dự đoán, nó không biết JOODB là gì.
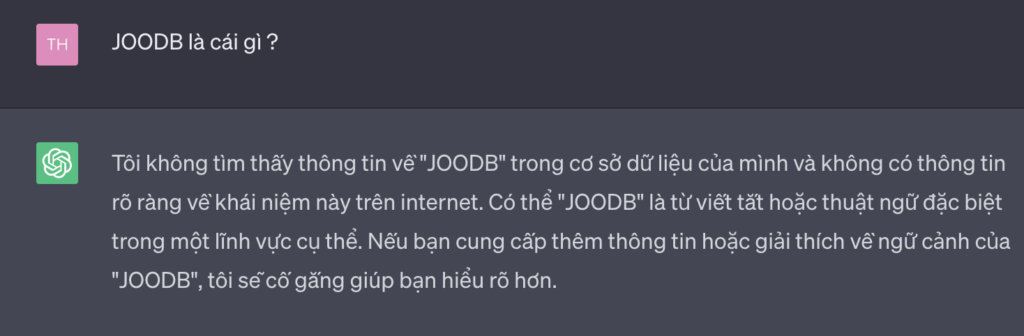
Fact: Joe T.Nartca là người thầy của mình từ congdongjava.com cách đây 13 năm trước, lúc mình mới tập tành code Java. JOODB là một bộ tài liệu mô tả cách bác ấy đã tạo ra một cơ sở dữ liệu hướng đối tượng, tức là đối tượng sẽ được lưu trữ vào trong CSDL. Mình đã học hỏi rất nhiều từ bác, với bài viết này cũng là một lời tri ân đến bác với các đóng góp của bác với congdongjava nói riêng và với các bạn làm Java ở Việt Nam nói chung.
Tổng kết
Qua bài viết này, chúng ta đã biết cách sử dụng LangChain để xây dựng một ứng chat được cung cấp dữ liệu từ các file PDF của chúng ta. Nó chỉ một trong những use-case đơn giản của một hệ thống AI thông minh.
Ngoài PDF, chúng ta cũng có thể cung cấp các dữ liệu khác như Youtube, dữ liệu từ Datawarehouse, dữ liệu text từ hình ảnh v.v Hoặc chúng ta cũng có thể thay thế OpenAI thành một LLM được chúng ta xây dựng riêng và triển khai riêng, nếu trong trường hợp bạn lo ngại dữ liệu nhạy cảm bị công bố.
Mình cũng hy vọng bài viết sẽ hỗ trợ các bạn lập trình viên hiện tại hiểu rõ hơn cách triển khai một ứng dụng AI từ LLM sẽ như thế nào. Để qua đó thúc đẩy tiến trình áp dụng AI tại Việt Nam.
Xin cám ơn.
Link Github: https://github.com/VnDataProduct/AI-Demo


{kind=link}