

Trong thời đại tiến bộ của khoa học dữ liệu, khả năng phân tích dữ liệu đã trở thành một kỹ năng cực kỳ quan trọng mà không thể bỏ qua.
Trong Series này, chúng ta sẽ bắt đầu một cuộc hành trình thú vị vào thế giới phân tích dữ liệu với Python, và điểm khởi đầu của chúng ta là thư viện Pandas. Pandas là một thư viện không thể thiếu, giúp chúng ta dễ dàng tiếp cận và xử lý dữ liệu từ việc đọc dữ liệu, tiền xử lý, thống kê, đến việc tạo biểu đồ và trực quan hóa dữ liệu.
Môi Trường Thực Thi & Thư Viện Của Python
Môi Trường
Môi trường thực thi Python là một phần mềm hoặc hệ thống mà bạn sử dụng để chạy mã Python. Nó có thể là một cài đặt Python trên máy tính của bạn hoặc một công cụ trực tuyến trên web
Có nhiều môi trường thực thi Python khác nhau. Một số môi trường thực thi Python phổ biến có thể kể đến như : Google Colab, Jupyter Notebook, Anaconda, Pycharm, Visual Studio Code. Và trong Series này chúng ta sẽ sử dụng Google Colab, là 1 nền tảng web của Google để đỡ tốn công cài đặt và đã được tích hợp sẵn các thư viện phổ biến
Thư Viện
Trong Python, một thư viện (library) là một tập hợp các module, lớp, hàm và tài nguyên đã được viết sẵn để giúp thực hiện các tác vụ cụ thể. Bằng cách sử dụng thư viện, bạn không cần phải viết mã từ đầu để thực hiện các tác vụ phức tạp, điều này giúp tiết kiệm thời gian và công sức. Ngoài ra, mỗi thư viện còn cung cấp 1 chức năng đặc biệt trong từng lĩnh vực cụ thể, ví dụ Pandas dùng cho việc phân tích và xử lý dữ liệu, Numpy dùng cho lĩnh vực tính toán số học…
Làm Quen Với Pandas
Import pandas & dataset
Đầu tiên bạn cần tạo 1 notebook trên Google Colab và import dataset cần phân tích vào notebook, ở đây mình sẽ dùng file csv


Tiếp theo import thư viện Pandas vào notebook, ở đây bạn sẽ thấy chỗ “as pd” có nghĩa là mình đang đặt định danh (alias) cho thư viện pandas nhằm mục đích gọi nhanh thư viện bằng chữ “pd” thay vì “pandas”
Trong Google Colab để thực thi code nhanh thì bạn có thể nhấn tổ hợp phím Ctrl + Enter hoặc Alt + Enter để chạy code và xuống dòng
import pandas as pdTiếp theo ta bắt đầu đọc dataset, bạn hãy click chuột phải vào dataset chọn “Copy Path” hay “Sao Chép Đường Dẫn” rồi paste vào câu lệnh như ảnh dưới ( ví dụ path của mình sẽ là “/content/train/csv” )
Ở đây mình đặt tên biến là “df”, biến df được sử dụng để lưu trữ dữ liệu từ hàm read_csv()
df = pd.read_csv()
#Để đọc dữ liệu từ file csv
df = pd.read_excel()
#Để đọc dữ liệu từ excel
#Ngoài ra pandas còn có thể đọc dữ liệu từ SQL, API nhưng mình sẽ không đề cập đến trong bài này
Dataset Overview
Lấy ra các hàng đầu tiên
Trong DataFrame của Pandas, mỗi hàng được gọi là một “record” hoặc “row”. Một DataFrame là một cấu trúc dữ liệu dạng bảng, và mỗi hàng của bảng đại diện cho một bản ghi (record)
df.head(10)
#Xem nhanh dữ liệu, số 10 có nghĩa là sẽ hiển thị ra 10 dòng đầu tiên của dataset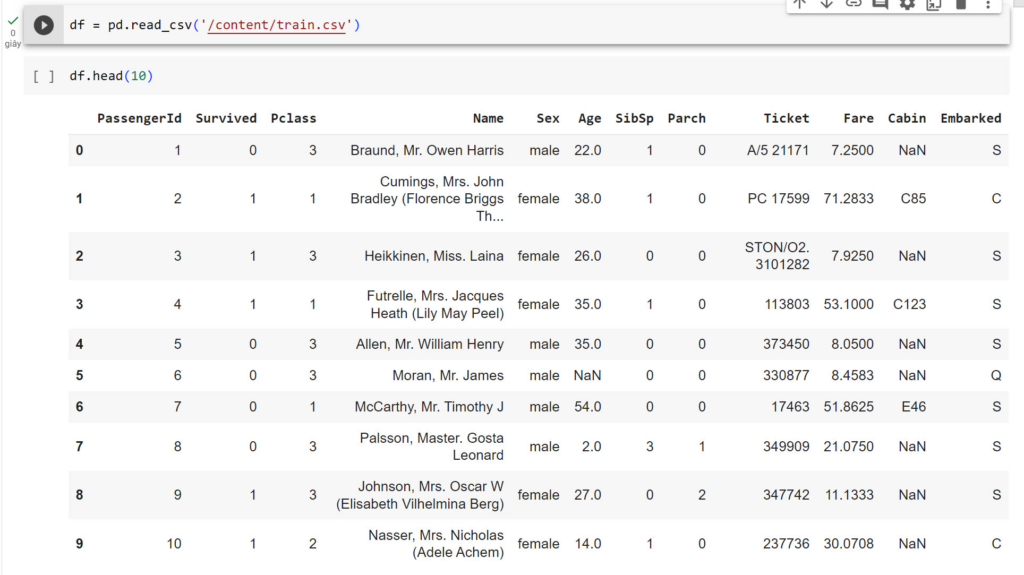
Lấy ra các hàng cuối cùng
df.tail(5)
#Tương tự, xem nhanh 5 dòng cuối cùng 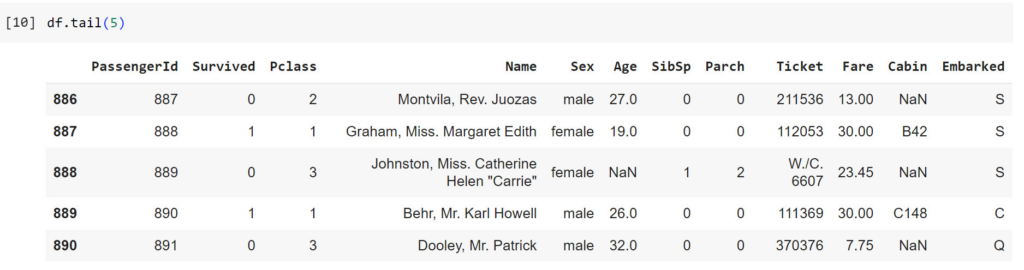
Thông tin Dataframe
df.info()
#Kiểm tra thông tin chi tiết như kiểu dữ liệu, số lượng cột và dòng, giá trị null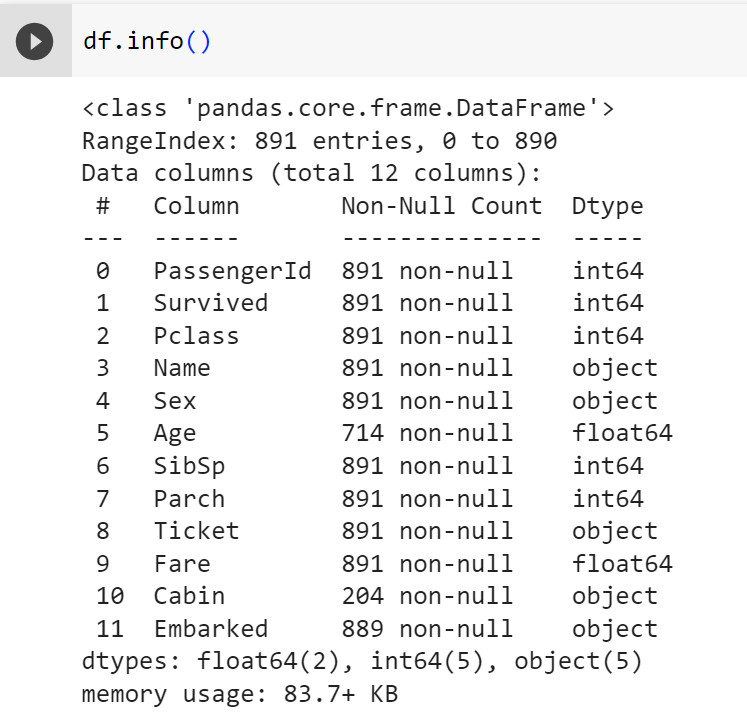
Dataframe này có 12 column, ví dụ column “PassengerId” sẽ có 891 giá trị không null ( không bị bỏ trống ) và kiểu dữ liệu là số nguyên (int64), column “Age” có 714 giá trị không null và kiểu dữ liệu là float64
Thống kê Dataframe
df.describe()
#Xem thống kê mô tả của dataframe như số lượng giá trị, mean, tứ phân vị...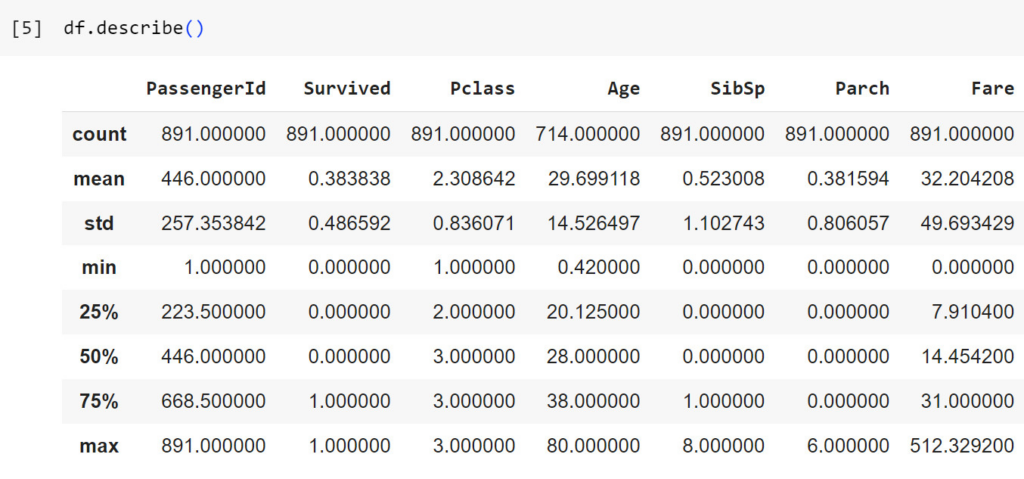
Ở đây ta sẽ thấy ví dụ cột “PassengerId” có 891 giá trị, giá trị trung bình là 446, STD (độ lệch chuẩn) là ~257, giá trị nhỏ nhất là 1, giá trị lớn nhất là 891, tứ phân vị lần lượt là 223.5, 446, 668.5
Truy cập vào Dataframe
df[['Column1','Column2',...]]
#Để lấy ra các hàng trong các cột chỉ định
#Ví dụ
df[['Age','Pclass']]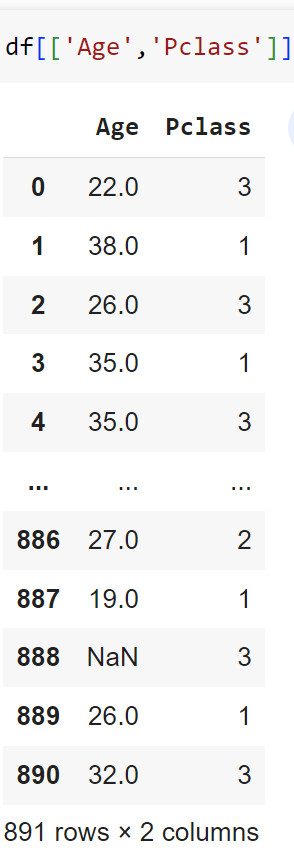
Lấy ra các hàng theo Index
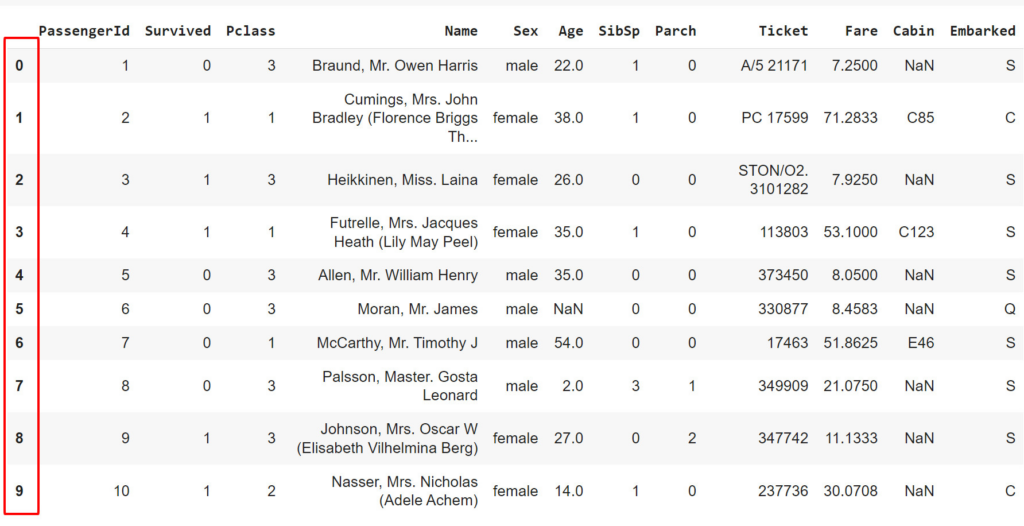
Tiếp theo chúng ta sẽ nói qua một chút về Index, có thể hiểu nôm na Index là một chuỗi các nhãn duy nhất được gán cho từng hàng trong DataFrame. Index giúp xác định một cách duy nhất mỗi hàng trong DataFrame và cho phép truy cập dữ liệu dễ dàng dựa trên nhãn của hàng. Mặc định thì Index sẽ được gắn nhãn từ 0 tương ứng với hàng 1 và tăng dần lên qua mỗi hàng
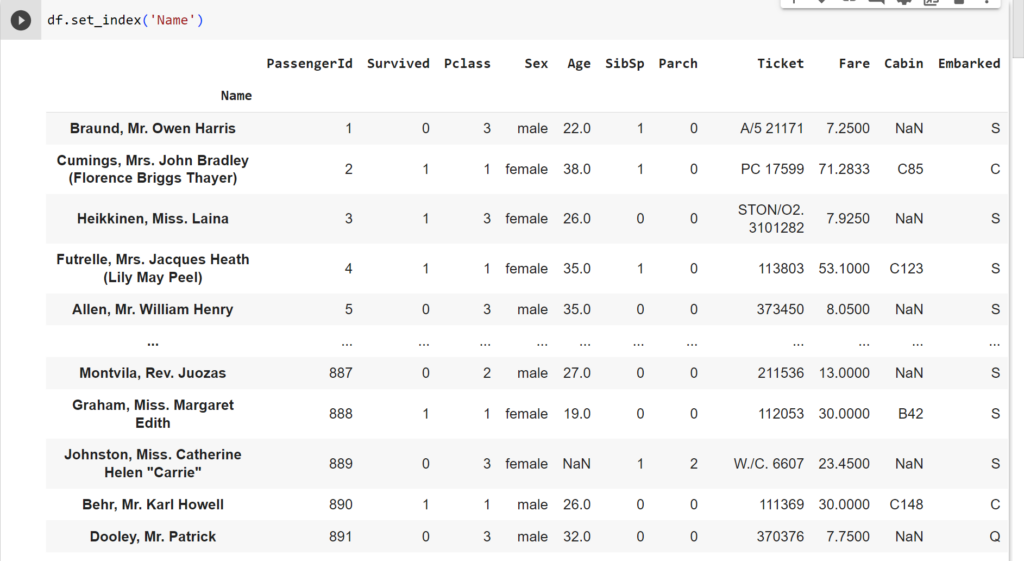
Và cần lưu ý rằng Index không phải là vị trí của hàng và nó có thể trùng lặp, nó chỉ là tên gọi của hàng đó (ví dụ để chỉ 1 hàng giá trị cho người khác biết thay vì chúng ta đọc từng cột để họ tìm xem là hàng nào thì chỉ cần nói nhanh hàng có index = 0). Chúng ta có thể dùng các cột khác để làm Index, ví dụ mình có thể lấy cột Name để làm Index
#Để truy cập vào 1 index cụ thể, ví dụ index = 9
df.iloc[[9]]
#Để truy cập vào index từ 3 đến 10
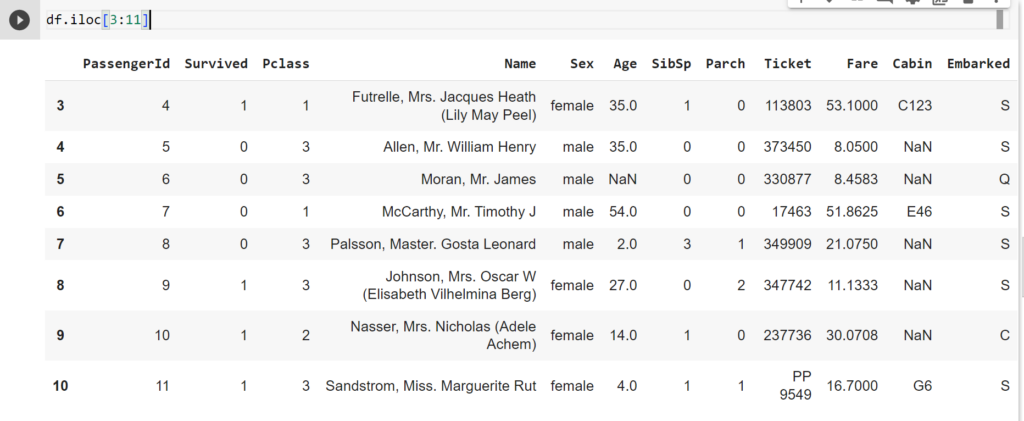
df.iloc[3:11]
#Lưu ý chỗ này vì sao điền 3:11 mà lại chỉ trả về 3 đến 10
#df.iloc[start_index: end_index]
#start_index: là chỉ số bắt đầu của con tập hợp dòng mà bạn muốn truy xuất (bao gồm).
#end_index: là chỉ số kết thúc của con tập hợp dòng mà bạn muốn truy xuất (không bao gồm)
#Nên khi điền 3:11 sẽ trả về từ 3 đến 10
Lấy ra các hàng theo điều kiện
Lưu ý tiếp theo trong Python cần phân biệt được = và ==.
= (Toán tử gán): Được sử dụng để gán giá trị cho một biến. Toán tử = gán giá trị của biểu thức bên phải cho biến bên trái. Khi bạn sử dụng =, bạn đang thực hiện một thao tác gán, không phải so sánh
#Ví dụ
x = 5 # Gán giá trị 5 cho biến x
y = x # Gán giá trị của biến x cho biến y và lúc này y = x = 5== (Toán tử so sánh bằng): Được sử dụng để so sánh hai giá trị có bằng nhau hay không. Khi bạn sử dụng ==, bạn đang thực hiện một phép so sánh giữa hai giá trị, kết quả trả về là True nếu hai giá trị bằng nhau và False nếu chúng khác nhau
#Ví dụ
a = 10
b = 5
result = a == b # So sánh giá trị của a và b
print(result) # Kết quả: FalseBây giờ để truy cập vào các hàng mà không biết Index hoặc có quá nhiều hàng thì chúng ta không thể liệt kê hết Index được. Chúng ta sẽ sử dụng df.loc thay vì df.iloc như trên
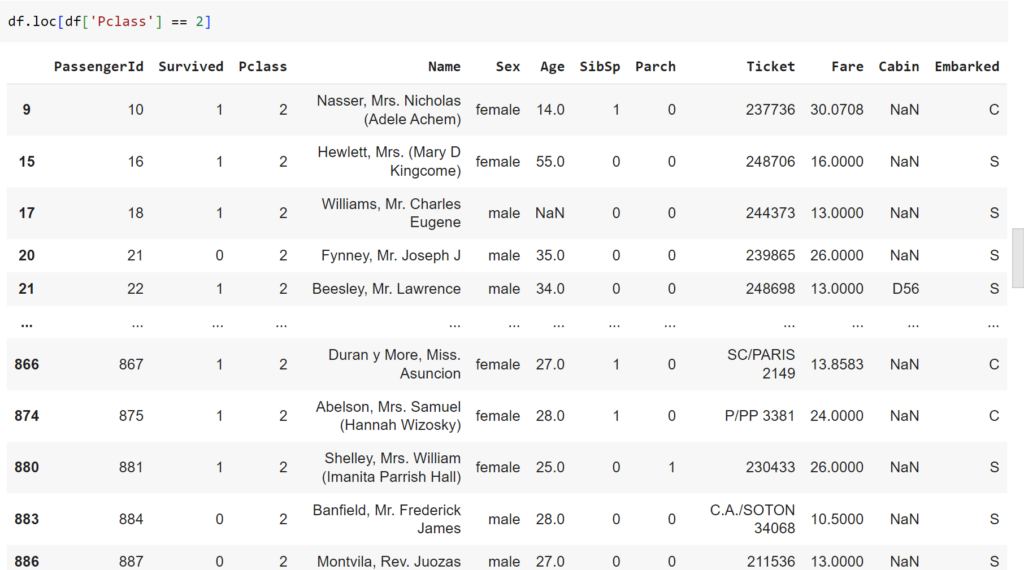
df.loc[df['Pclass'] == 2]
#Lấy ra các hàng có Pclass = 2
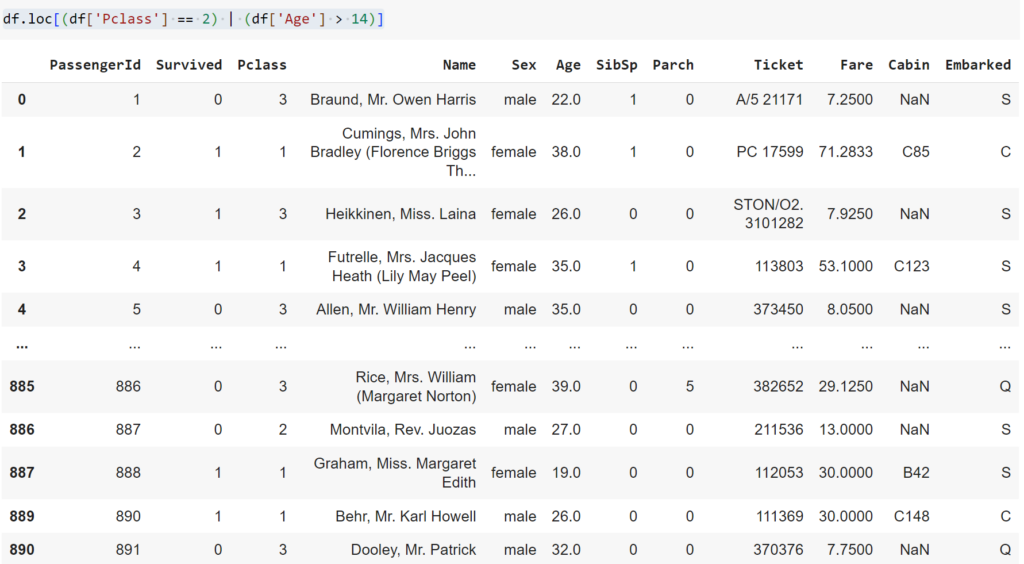
df.loc[(df['Pclass'] == 2) | (df['Age'] > 14)]
#Hoặc kết hợp nhiều điều kiện, lấy ra các hàng có Pclass = 2 và Age > 14. Dấu | tượng trưng cho chữ Hoặc
Preprocessing Data
Xóa các hàng có giá trị Null
Đầu tiên chúng ta sẽ kiểm tra xem tổng giá trị null của từng cột
df.isnull().sum()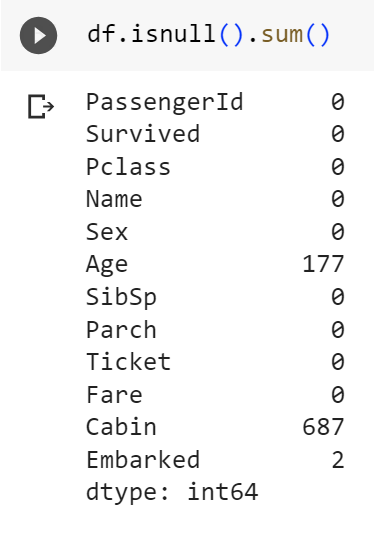
Ở cột “Age” có 177 giá trị null, cột “Cabin” có 687 giá trị null và cột “Embarked” có 2 giá trị null. Cách nhanh nhất để xử lý các giá trị null này là xóa bỏ các hàng có giá trị null
df.dropna()
#Xóa các hàng có giá trị null, chỉ cần 1 hàng có 1 giá trị null bất kì trong 12 cột thì cả hàng này sẽ bị xóa
df.dropna(subset=['Age'])
#Xóa các hàng có giá trị null tại cột "Age", các cột khác null mà "Age" không bị null thì sẽ giữ lại không xóa. Có thể thay cột "Age" bằng các cột khácTa cần lưu ý 1 vấn đề, khi thực thi câu lệnh df.dropna() nó sẽ trả về một phiên bản DataFrame mới với các hàng chứa nullđã được loại bỏ. Nó không thay đổi df gốc, nếu ở cell tiếp theo chúng ta gọi lại df thì vẫn sẽ là DataFrame ban đầu, nên để lưu kết quả và sử dụng tiếp, bạn cần gán nó cho một biến mới hoặc chính biến df
df = df.dropna()
#lưu dataframe đã được loại bỏ null vào df
new_df = df.dropna()
#lưu dataframe đã được loại bỏ null vào new_df còn df ban đầu vẫn không đổi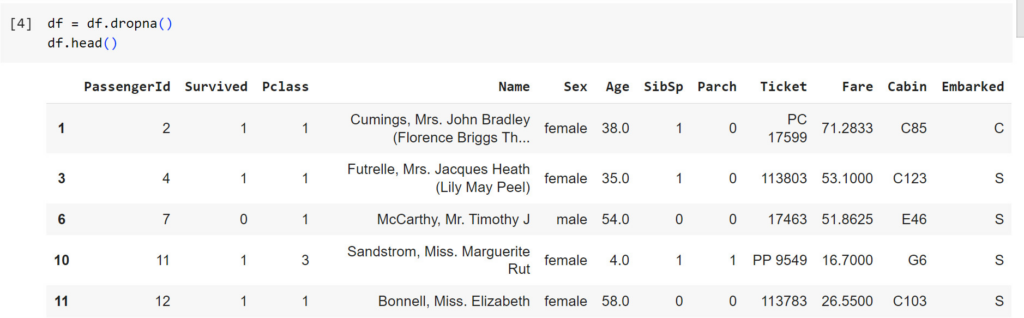
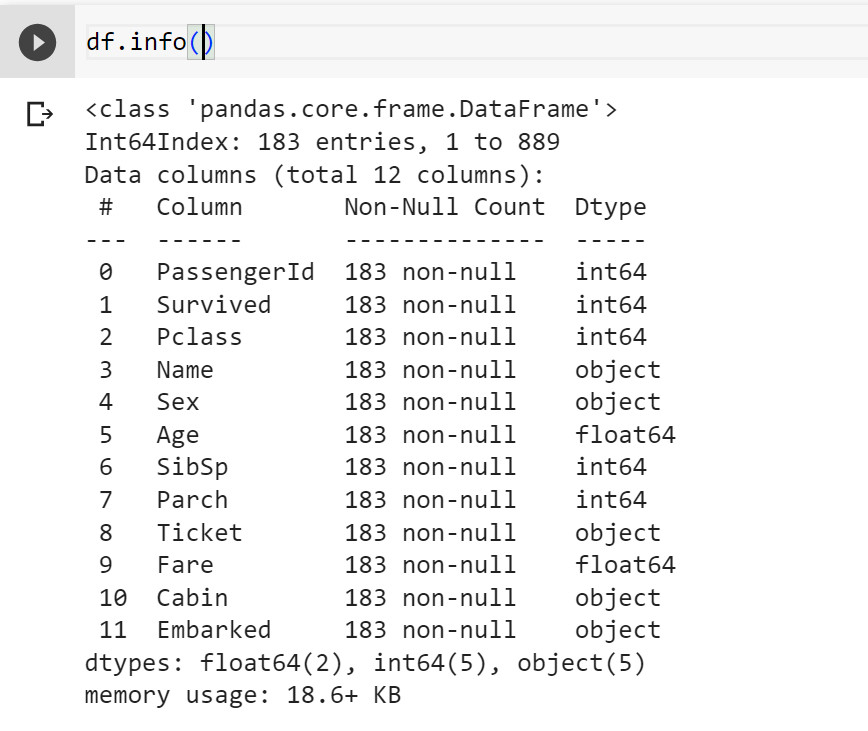
Sau khi dropna() thì chạy lại df.info() , bây giờ từ 891 dòng thì chỉ còn lại 183 dòng giá trị không null ở tất cả các cột
Fill giá trị null
Dễ dàng nhận ra 1 vấn đề khi xóa bỏ hết các hàng có giá trị null ở 1 cột đó là bị mất rất nhiều dữ liệu, bây giờ mình sẽ thử 1 cách khác.
Trước khi dropna thì ta có cột “Cabin” là có nhiều giá trị null nhất ( 687 null ) nên mình sẽ xóa cột này đi
df.drop('Cabin',axis=1,inplace=True)
#Đây là phương thức để xóa bỏ hàng hay cột, ở đây mình muốn xóa bỏ cột "Cabin"
#Axis = 1 nghĩa là xóa cột, Axis = 0 nghĩa là xóa hàng
#inplace = True thay thế nhanh cho df = df.drop('Cabin',axis=1) để gán lại cho df ban đầu
#Nếu muốn xóa bỏ cùng lúc nhiều cột thì phải đưa tên các cột vào dấu "[]" để truyền 1 list
#Ví dụ
df.drop(['Sex','Age','Cabin'],axis=1,inplace=True)Sau khi xóa cột “Cabin” thì ta gọi lại hàm df.isnull().sum() để kiểm tra lại sẽ thấy cột “Cabin” đã biến mất. Và sẽ xử lý tiếp null của 2 cột “Age” và “Embarked”
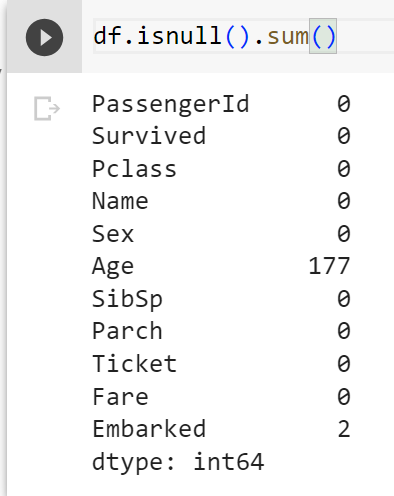
Với “Embarked” chỉ có 2 giá trị null nên mình sẽ dropna luôn cho nhanh và nó cũng sẽ không ảnh hưởng đến DataFrame có 891 hàng
df.dropna(subset=['Embarked'],inplace=True)Median & Mean
Median
Medan (Trung vị) là vị trí giữa khi tập dữ liệu được sắp xếp theo thứ tự tăng dần hoặc giảm dần. Điều này có nghĩa là 50% dữ liệu nằm trên giá trị median và 50% dữ liệu nằm dưới giá trị median
Median thường được sử dụng khi tập dữ liệu chứa nhiều giá trị ngoại lệ (outliers), tức là các giá trị rất lớn hoặc rất nhỏ so với các giá trị còn lại, vì nó không bị ảnh hưởng quá nhiều bởi các giá trị ngoại lệ
Ví dụ: Có 5 khách hàng mua hàng với các độ tuổi lần lượt là : 14, 15, 16, 17, 80. Thì Median = 16 ( vị trí nằm ở giữa )
Mean
Mean (Trung bình) là tổng của tất cả các giá trị trong tập dữ liệu chia cho số lượng các giá trị
Mean dễ bị ảnh hưởng bởi các giá trị ngoại lệ (outliers) trong tập dữ liệu. Nếu có các giá trị ngoại lệ, chúng có thể làm thay đổi rất nhiều giá trị trung bình của tập dữ liệu
Ví dụ như trên: Có 5 khách hàng mua hàng với các độ tuổi lần lượt là : 14, 15, 16, 17, 80. Thì Mean = (14 + 15 + 16 + 17 + 80)/5 = 28.4
-> Khi xuất hiện 1 giá trị ngoại lệ thì giá trị trung bình này sẽ bị lệch hẳn về 1 phía, và dễ gây ra insight sai lầm khi cho rằng độ tuổi trung bình của khách hàng là 28.4
Quay lại với dataset, chỉ còn giá trị null tại cột “Age” thì mình sẽ tính độ tuổi trung vị theo “Sex” và “Pclass” của DataFrame này
median_age = df.groupby(['Pclass','Sex'])['Age'].transform('median')
#Groupby ở đây có thể hiểu như pivot table ở excel, là nhóm lại theo "Pclass" và "Sex"
#Đầu tiên nó sẽ nhóm lại dataframe theo "Pclass" và "Sex", sau đó tính độ tuổi trung vị, cuối cùng biến đổi toàn bộ "Age" = "Age" trung vị
#Ví dụ "Pclass" = 1 & "Sex" = male có độ tuổi trung vị = 20, thì tại mọi nơi có "Pclass" = 1 & "Sex" = male thì sẽ biến đổi tuôi = 20 hếtdf['Age'].fillna(median_age,inplace=True)
#Bổ sung giá trị median_age đã tính ở trên vào các nơi bị null trong cột "Age"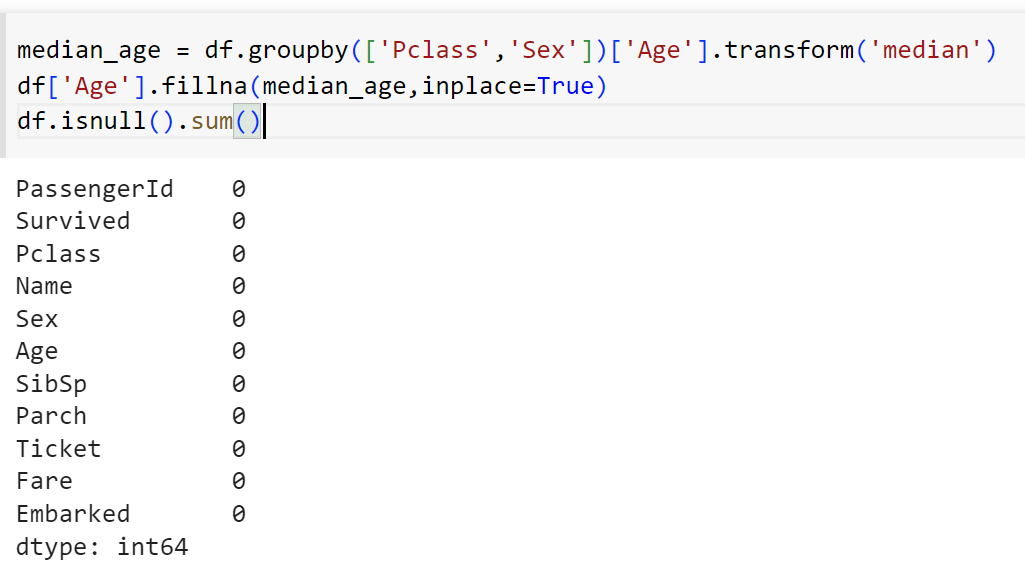
Sau một loạt thao tác xử lý thì các giá trị null đã không còn. Các bạn có thể dựa vào tình huống cụ thể và mục tiêu để xác định cách xử lý dữ liệu bị Null trong DataFrame
Khi số lượng giá trị null trong DataFrame không quá lớn và không ảnh hưởng đáng kể đến khía cạnh quan trọng của dữ liệu, bạn có thể chọn loại bỏ các dòng hoặc cột null
Khi số lượng giá trị null trong DataFrame quá nhiều hoặc đó là thông tin quan trọng không nên bị mất, bạn nên xem xét điền giá trị thích hợp cho các ô null để giữ được sự đầy đủ của dữ liệu
Groupby
Mình sẽ nói sâu hơn về phần Groupby đã đề cập ở trên. Để dễ hiểu thì đi vào ví dụ
df.groupby('Sex')['PassengerId'].count()
#Đếm số lượng hành khách theo "Sex"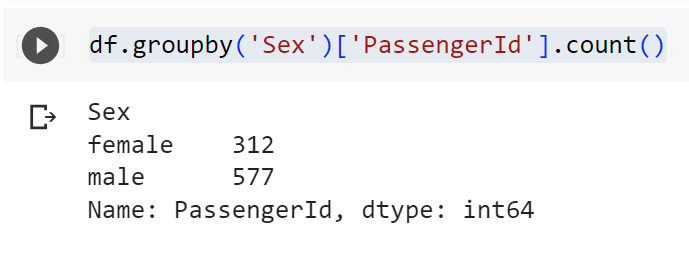
Có 312 hành khách có giới tính là nữ và 577 hành khách giới tính nam
df.groupby(['Sex','Pclass'])['PassengerId'].count()
#Đếm số lượng hành khách theo "Sex" và "Pclass". Như đã nói ở trên, vì có nhiều hơn 1 cột nên cần đưa vào list, trong dấu "[]"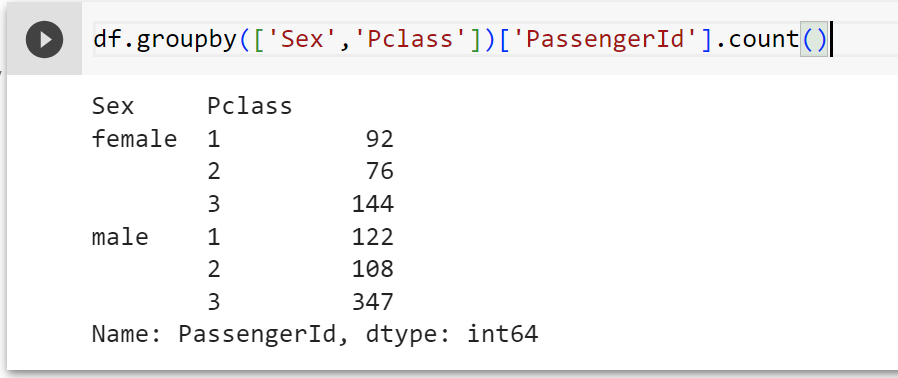
Có 92 hành khách giới tính nữ ở class 1, 76 hành khách giới tính nữ ở class 2… có 347 hành khách giới tính nam ở class 3
df.groupby(['Sex','Pclass'])['Age'].mean()
#Độ tuổi trung bình theo "Sex" & "Pclass"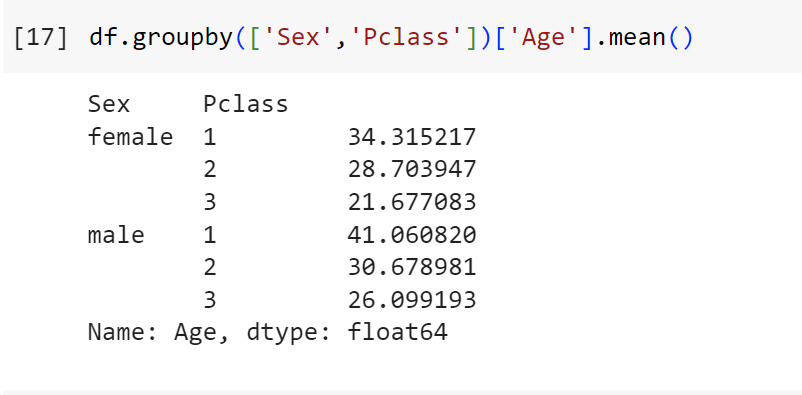
df.groupby(['Sex','Pclass'])['Age'].median()
#Độ tuổi trung vị theo "Sex" & "Pclass"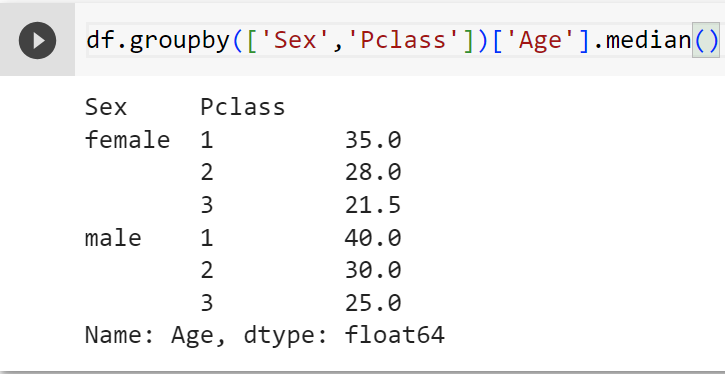
Tạo thêm cột dựa trên điều kiện
Ví dụ mình cần tạo thêm 1 cột để phân loại hành khách nhỏ hơn 18 tuổi, từ 18 đến 25 tuổi và trên 25 tuổi
df['age_group'] = 'other'
df.loc[df['Age'] < 18,'age_group'] = '<18'
df.loc[(df['Age'] >= 18) & (df['Age'] <= 25),'age_group'] = '18 - 25'
df.loc[df['Age'] > 25,'age_group'] = '>25'
#Đầu tiên sẽ tạo ra 1 cột tên là "age_group" và toàn bộ giá trị của cột này = 'other'
#Sau đó chúng ta sử dụng df.loc như ở trên đã nhắc đến để tìm ra các điều kiện
#Ví dụ với những hành khách có "Age" < 18 thì sẽ biến đổi giá trị ở cột 'age_group' = '<18'
#Một số trường hợp có thể kết hợp với thư viện Numpy để tạo cột nhanh hơn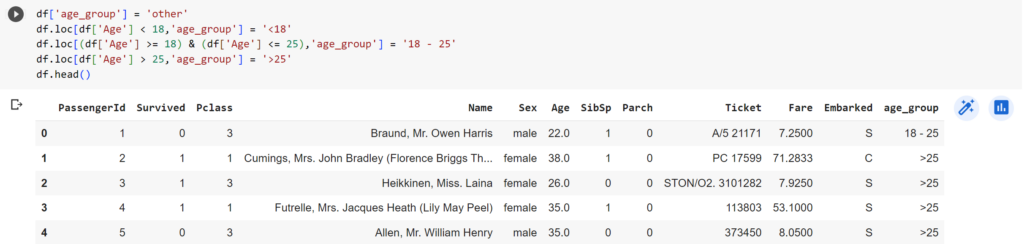
Visualization
Trong Pandas, ta có thể thực hiện một số tác vụ trực quan hóa dữ liệu đơn giản để hiểu và trực quan hóa thông tin trong DataFrame. Nếu cần vẽ các chart chuyên sâu hơn và phức tạp hơn thì Pandas không thể đáp ứng được mà cần dùng các thư viện khác như Matplotlib, Seaborn, Plotly…
df.groupby('Sex')['PassengerId'].count().plot(kind='bar')
#Biểu đồ là barchart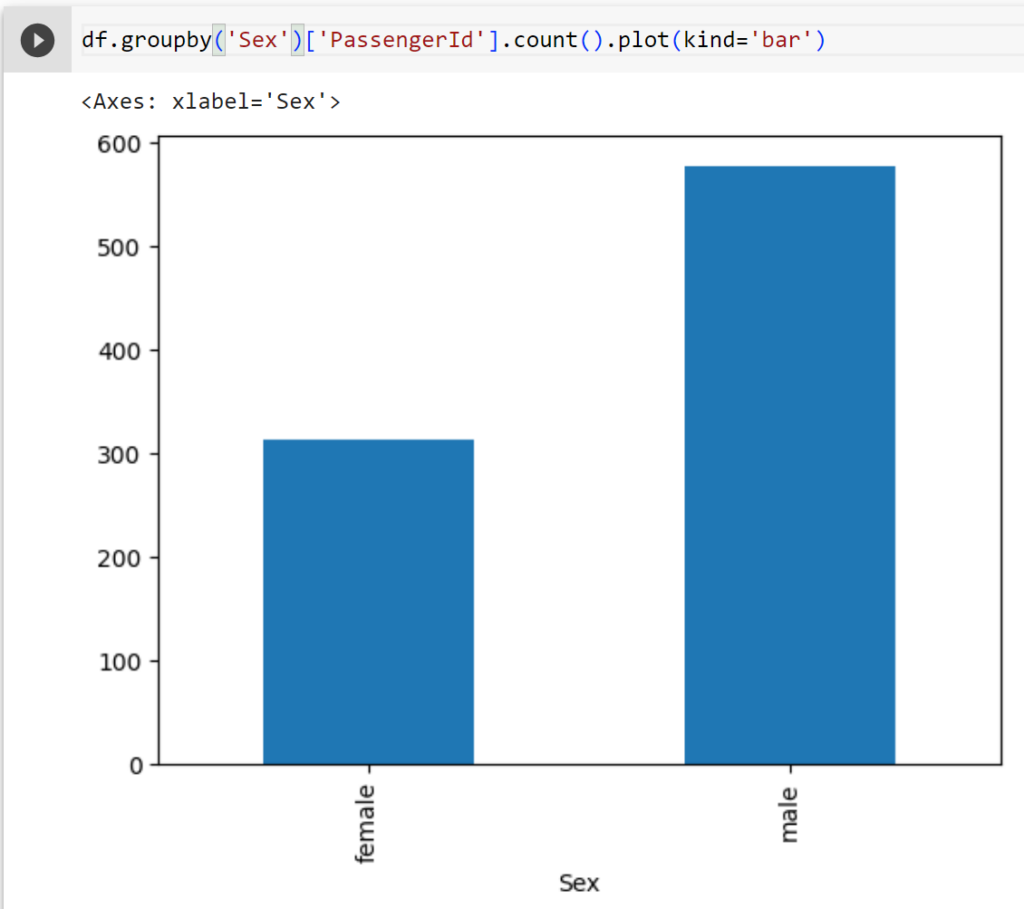
df.groupby('Pclass')['PassengerId'].count().plot(kind='pie')
#Biểu đồ tròn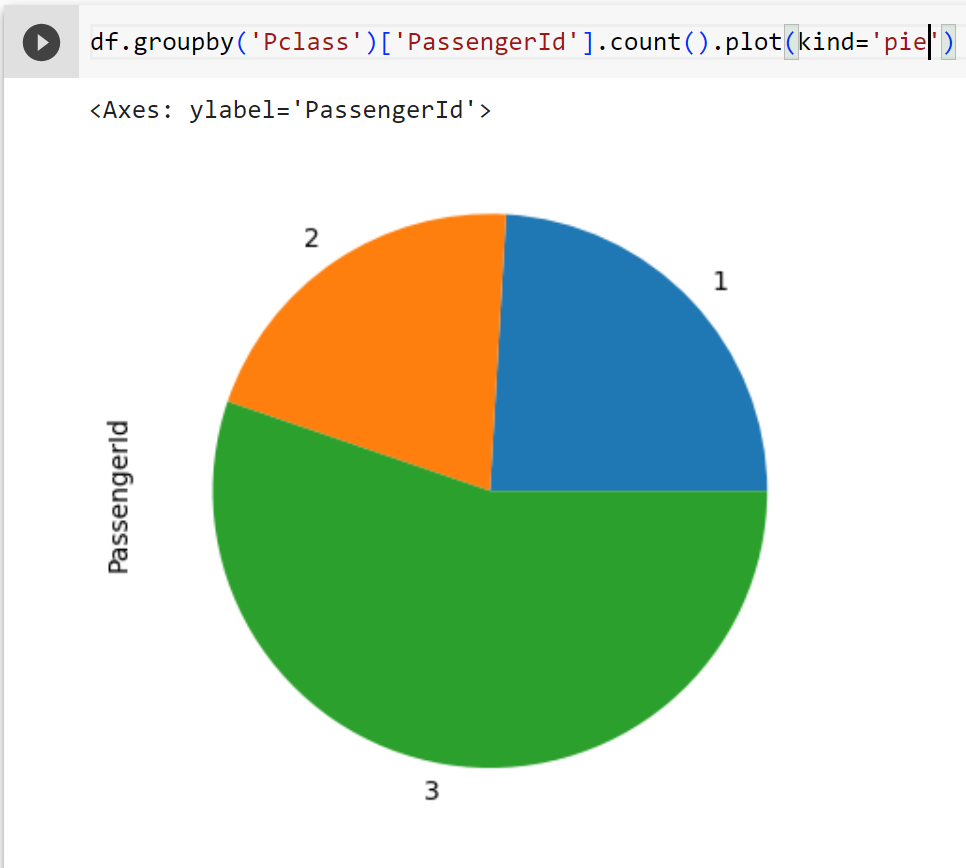
df.groupby('Pclass')['PassengerId'].count().plot(kind='line')
#Biểu đồ đường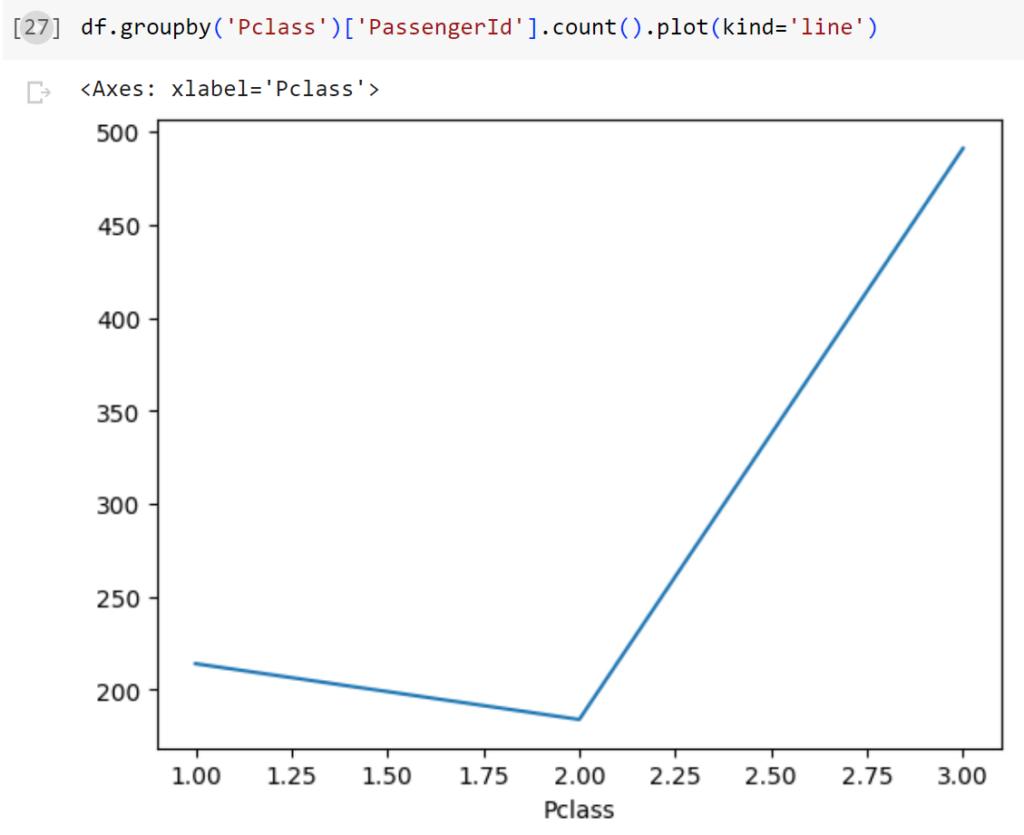
Ngoài ra còn các biểu đồ khác như Hist, Box, Scatter… các bạn có thể tự tìm hiểu thêm
Vậy là chúng ta đã làm quen xong với thư viện Pandas. Ngoài những nội dung trên thì Pandas còn rất nhiều ứng dụng khác chuyên sâu như preprocessing cho Machine Learning mà mình không đề cập đến trong bài
Hy vọng bài viết này sẽ giúp ích được cho bạn


{kind=link}