
Đều được sử dụng trong việc thiết kế data model của Data Warehouse hoặc Data Mart. Dưới đây là phân biệt giữa Star schema và Snowflake schema.
Star schema
Giống như tên, Star schema được thiết kế tương tự như một ngôi sao. Trong đó, có một bảng dữ liệu fact (bảng thống kê) nằm ở trung tâm thiết kế, xung quanh bảng fact này là các bảng dimensions chứa các dữ liệu mang tính đối tượng (object) liên quan tới bảng fact.
Star Schema là cách thiết kế đơn giản nhất trong Data Warehouse. Tuy nhiên, nó lại được sử dụng rất phổ biến vì cách thiết kế đơn giản và đặc tính tối ưu hóa của nó trong việc truy xuất dữ liệu.
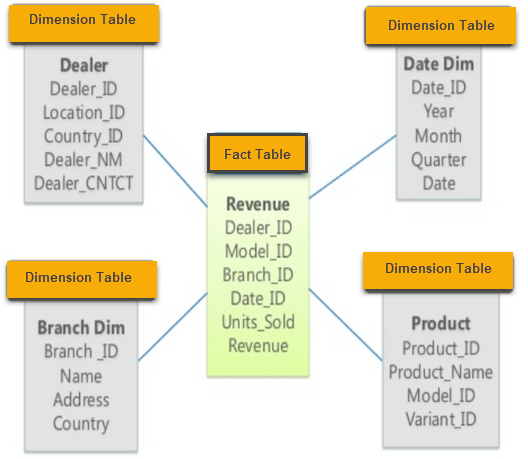
Ví dụ: hình dưới đây là thiết kế thống kê số lượng bán, doanh thu (nằm trong Fact Table: Revenue) dựa trên thời gian, người bán, nơi bán và sản phẩm bán (nằm trong 04 bảng Dimension).
Snowflake schema
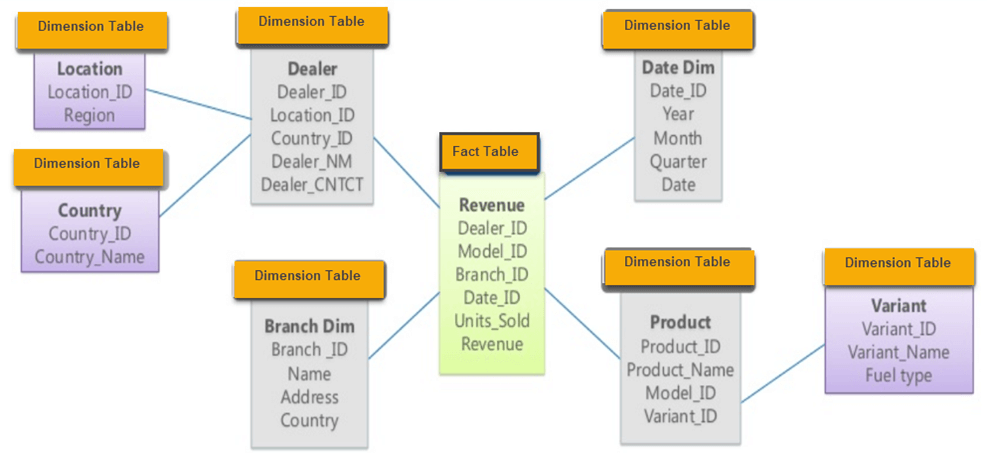
Là bảng nâng cấp của Star schema, Snowflake schema chuẩn hóa (normalize) các bảng dimension thành các bảng dimension phụ trợ cho các bảng dimension trong Star schema. Hình ảnh thiết kế của Snowflake schema khá giống với hình ảnh bông tuyết, một trung tâm và tẻ ra nhiều nhánh, nên được đặt tên là Snowflake.
Ví dụ: chúng ta sẽ lấy lại ví dụ trên. Tuy nhiên các bảng dimension sẽ được tách ra theo đúng cấu trúc đối tượng.
Bảng so sánh
Dưới đây là các điểm chính để phân biệt giữa Star schema và Snowflake schema:
| Star Schema | Snowflake Schema |
|---|---|
| Các đối tượng phụ xung quanh đối tượng chính sẽ được xây dựng chung một bảng dimension. | Các đối tượng phụ và đối tượng chính được xây dựng tách bạch. |
| Các bảng dimension được xây dựng xung quanh một bảng fact. | Với bảng fact là trung tâm, các bảng đối tượng được xây xung quanh, đồng thời còn các đối tượng phụ xung quanh đối tượng chính. |
| Star schema chỉ cần một câu lệnh join để trả về dữ liệu giữa bảng fact và các bảng dimension. | Snowflake schema cần nhiều câu lệnh join để xây dựng dữ liệu trả về. |
| Thiết kế cơ sở dữ liệu đơn giản. | Thiết kế cơ sơ dữ liệu tương đối phức tạp. |
| Các đối tượng dữ liệu được dàn trải hàng ngang nên truy xuất nhanh hơn. | Các dữ liệu đối tượng được chuẩn hóa đúng theo đối tượng đó. |
| Các dữ liệu bị lặp lại khá nhiều. | Dữ liệu lặp lại ít hoặc không có. |
| Một đối tượng chính sẽ được tổng hợp từ nhiều đối tượng phụ vào chung một bảng. | Đối tượng chính được tách ra thêm các đối tượng phụ xung quanh. |
| Truy xuất dữ liệu theo nhu cầu (datacube) sẽ nhanh hơn. | Truy xuất dữ liệu theo nhu cầu sẽ chậm hơn do phải join nhiều bảng. |


{kind=link}