
Xin chào các bạn đến với chuỗi bài xử lý dữ liệu từ website thông qua đầu HTTP tracker. Ở phần trước chúng ta đã làm quen với việc build dữ liệu trên Star schema và cài đặt pg_cron. Ở phần này chúng ta sẽ đi sâu hơn với bài thống kê các chỉ số định danh trên PostgreSQL thông qua thuật toán đếm xấp xỉ hyperloglog.
Đặt vấn đề
Quay lại yêu cầu từ bài 01:

Chúng ta thấy vẫn còn yêu cầu thứ ba mà ở các bài trước mình vẫn chưa giải quyết được. Đặt bài toán, giờ mình sẽ xây dựng các bảng dữ liệu FACT, cộng với gắn tài khoản người đăng ký. Thì chắc bạn đã nhận ra rằng nó gần như là dữ liệu thô. Ví dụ nhé:
| time | device | … | event_count | account_id |
| 2023-01-01 22:00:00 | 1 | … | 1 | 1 |
| 2023-01-01 22:00:00 | 2 | … | 1 | 2 |
Vì chúng ta phải giữ nguyên account_id, để có thể sum lại theo ngày hoặc sum lại theo device, để có thể đếm chính xác số lượng account_id. Chắc bạn đã nhận ra rằng, bảng dữ liệu này hoàn toàn không phải bảng FACT và về lâu dài nó sẽ càng nặng và khó truy vấn.
Hướng giải quyết
May thay, chúng ta có thể sử dụng thư viện Postgres-HLL. Giới thiệu nhanh về thư viện, nó sẽ giúp bạn các bài toán về đếm các tập hợp. Ví dụ bạn muốn thống kế số lượng người dùng sử dụng máy tính bàn và trình duyệt là Chrome trong vòng 3 ngày, 7 ngày, 10 ngày.
Bạn có thể chuẩn bị sẵn, tuy nhiên điều kiện truy vấn chỉ cần thay đổi một chút là dường như bạn phải làm lại từ đầu. Ví dụ sử dụng điện thoại nhưng trình duyệt là Fire Fox và chỉ trong 5 ngày. Không lối thoát nhỉ?
Tuy bộ thuật toán HLL này có thể giúp bạn đếm các tập hợp nhanh, dữ liệu lưu trữ không lớn. Nhưng đồng thời bạn phải hy sinh độ chính xác, tầm vài % trở lại. Sẽ là không đáng kể đối với các bài toán thống kê và báo cáo.
Thực hành
Vẫn dùng lại Postgres trên Docker chúng ta đã khởi tạo và thực hành ở những bài trước. Lần này chúng ta sẽ truy cập vào container Postgres: “docker exec -it <my-postgres-container> bash“.
Cài đặt Postgres-HLL
apt-get install -y wget
apt-get install -y unzip
apt-get install -y postgresql-server-dev-15
apt-get install -y postgresql-server-dev-15 make gcc g++Sau đó, bạn chạy các câu lệnh sau để tải postgres-hll về để có thể build trên container postgres.
wget https://github.com/citusdata/postgresql-hll/archive/refs/heads/master.zip -P /tmp
unzip /tmp/master.zip -d /tmp/
cd /tmp/postgresql-hll-master
PG_CONFIG=/usr/bin/pg_config make
PG_CONFIG=/usr/bin/pg_config make installLúc này bạn đã build xong bộ thư viện vào trong Postgres. Bạn chỉ cần restart lại docker Postgres. Sau đó, kết nối vào vào Postgres bằng dbeaver, rồi dùng đoạn lệnh sau:
CREATE EXTENSION hll;Chúc mừng bạn đã hoàn thành cài đặt bộ thư viện. Chúng ta sẽ qua bước thử nghiệm kết quả.
Thử nghiệm
Trước hết chúng ta sẽ thêm vào một ít dữ liệu test nhé:
insert into raw_data (event_time, device, browser, result, message, duration, account_id)
values
('2023-02-28 11:44:33.322', 'Desktop', 'Firefox', 'success', 'OK', 3883, 857),
('2023-02-28 11:53:11.439', 'Desktop', 'Chrome', 'success', 'OK', 2392, 857),
('2023-02-28 12:28:49.852', 'Desktop', 'Firefox', 'success', 'OK', 1292, 857),
('2023-02-28 11:16:58.578', 'mobile', 'Chrome', 'success', 'OK', 539, 17289),
('2023-02-28 12:27:12.019', 'Desktop', 'Microsoft Edge', 'success', 'OK', 7893, 3738);Sau đó, bạn chạy thử đoạn SQL dưới đây để xem bộ thư viện Postgres-HLL xây dựng dữ liệu như thế nào nhé:
SELECT date_trunc('hour', event_time), hll_add_agg(hll_hash_integer(account_id))
FROM raw_data rd
GROUP BY 1;
Bỏ qua dữ liệu ngày 22, thì với dữ liệu test ngày 28
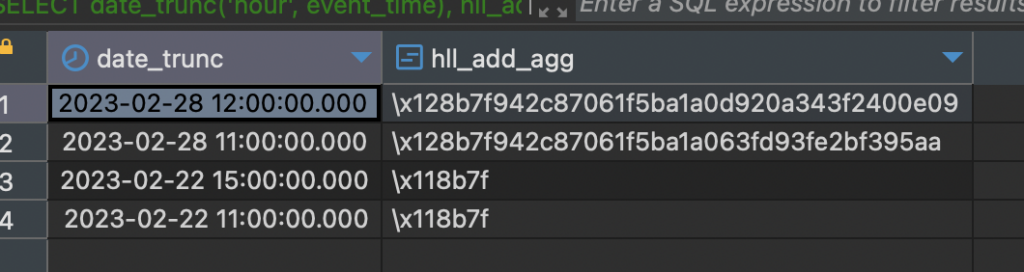
Okay, dữ liệu ra một đống kí tự “lạ”, thật ra nó là chuỗi băm cột account_id vào cột dữ liệu. Bạn để ý giờ 11 và giờ 12 nhé, nhìn 02 chuỗi băm rất khác nhau. Vậy chúng ta thử đếm xấp xỉ xem sao nhé:
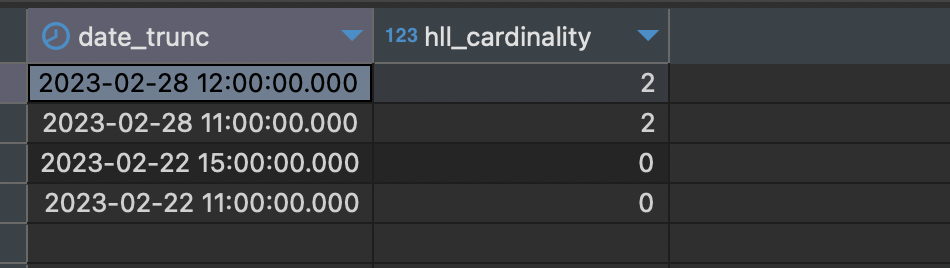
SELECT date_trunc('hour', event_time), hll_cardinality(hll_add_agg(hll_hash_integer(account_id)))
FROM raw_data rd
GROUP BY 1;Kết quả sẽ như bên dưới. Bạn sẽ thấy kết quả đều bằng 02, dù mã băm khác nhau. Mã băm từ HLL sẽ giúp chúng ta giúp tính toán nhiều tập hợp với nhau.
Bây giờ, chúng ta sẽ tiến hành thêm cột num_accounts vào bảng fact_tracking_data. Đồng thời sửa lại procedure proc_build_fact_data build dữ liệu.
-- We alter the table to add new column
alter table public.fact_tracking_data add column num_accounts public.hll;
-- We replace the procedure with new code (num_accounts)
CREATE OR REPLACE PROCEDURE public.proc_build_fact_data(IN _from timestamp without time zone, IN _to timestamp without time zone DEFAULT CURRENT_TIMESTAMP)
LANGUAGE plpgsql
AS $procedure$BEGIN
delete from public.fact_tracking_data where "time" between _from and _to;
insert into public.fact_tracking_data
(select date_trunc('hour', event_time) as time,
dd.id as device ,
bd.id as browser ,
(case when lower(rd.result) = 'success' then true else false end) as success,
md.id as message,
sum(rd.duration) as total_duration,
sum(1) as event_count,
hll_add_agg(hll_hash_integer(account_id)) as num_accounts
from raw_data rd
left join message_dim md on lower(md.message) = lower(rd.message)
left join device_dim dd on lower(dd.device_name) = lower(rd.device)
left join browser_dim bd on lower(bd.browser_name) = lower(rd.browser)
where rd.event_time between date_trunc('hour', _from) and date_trunc('hour', _to + interval '1' hour)
group by 1, 2, 3, 4, 5);
END$procedure$;
-- We will build proc data again
call public.proc_build_fact_data('2023-01-01 00:00:00'); Chúng ta chạy thử đoạn SQL sum theo ngày sau và kiểm chứng lại dữ liệu nhé.
select date_trunc('day', time), #(hll_union_agg(num_accounts)) as acc_count from fact_tracking_data ftd group by 1;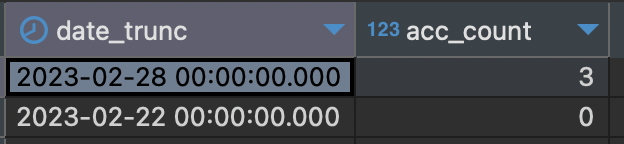
Tóm tắt
Qua bài này, chúng ta đã biết thêm được cách để đếm xấp xỉ các chỉ số định danh. Trong thực tiếp, việc thống kê các chỉ số định danh rất phiền phức nếu không có HLL hỗ trợ. Ví dụ: thống kê số lượng users theo ngày tháng năm hoặc số lượng thiết bị sử dụng phần mềm. Đối với những bài toán này, chúng ta có thể hy sinh một ít tính chính xác tuyệt đối, mà đảm bảo được việc báo cáo nhanh và giảm tải hệ thống.
Hy vọng qua bài này, các bạn có thêm công cụ để hỗ trợ các tác vụ liên quan tới data. Kết thúc bài này, cũng sẽ kết thúc chuỗi bài HTTP tracker. Vì chúng ta làm data thì phải có data-driven, đồng thời các dữ liệu báo cáo cho thấy xu hướng tìm kiếm các kiến thức cơ bản dễ được người đọc tìm kiếm hơn. Nên mình quyết định sẽ quay về viết các bài ở mức độ cơ bản phục vụ đúng nhu cầu người đọc.
Xin cám ơn các bạn đã ủng hộ.


{kind=link}