
Ở bài trước trong chuỗi bài SQL trong Data Analysis, chúng ta đã học một số từ khoá nâng cao trong Window Functions. Ở bài này chúng ta sẽ đi qua một số từ khoá tuy ít thông dụng hơn một chút nhưng vẫn ở chuyên mục nâng cao, và đôi khi sẽ giúp chúng ta giải quyết vấn đề một cách đơn giản hơn.
Thực hành
CUME_DIST
Từ khoá CUME_DIST dùng để tính tỉ lệ cộng dồng giá trị phân phối của một giá trị cột cụ thể trong nhóm phân loại của nó. Từ CUME_DIST là viết tắt của cumulative distribution, dịch là phân phối tích luỹ.
select product_id, product_category_name, product_name_lenght, CUME_DIST() OVER (
PARTITION BY product_category_name
ORDER by product_name_lenght
)
from "brazilian-ecommerce".olist_products_dataset;Kết quả
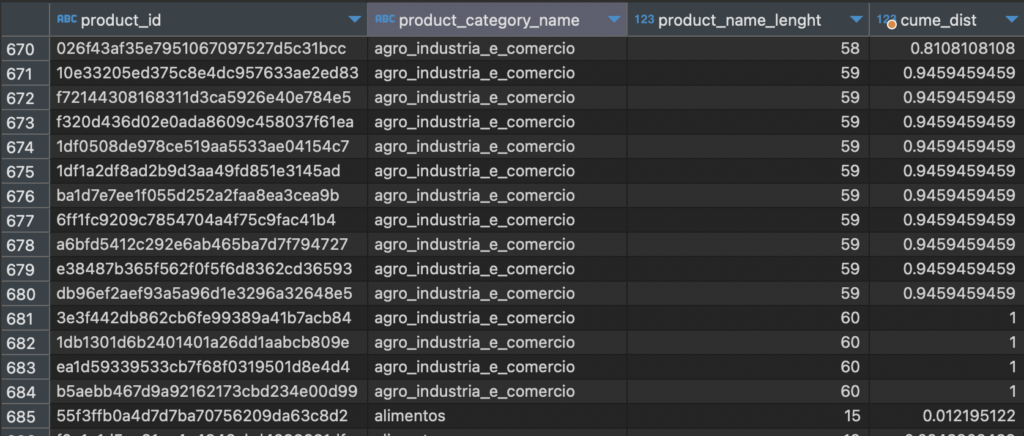
Như kết quả trên, bạn sẽ thấy là với category là agro_industria_e_comercio và lenght là 59 hoặc 60 thì chúng có kết quả trong cột cume_dist là giống nhau. Ở đây có thể hiểu là tới 94.59% sản phẩm có length nhỏ hơn hoặc bằng 59.
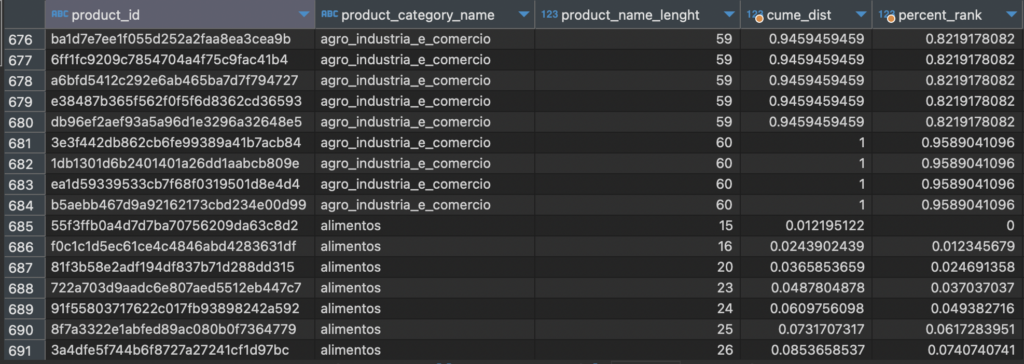
Note: nếu bạn đã học qua phần PERCENT_RANK, bạn có thể thấy 02 từ khoá có vẻ khá giống nhau. Tuy nhiên CUME_DIST thì tính các giá trị tính từ các dòng trước đó cho đến chính nó, còn PERCENT_RANK chỉ tính các trị nhỏ hơn nó. Thử truy vấn dưới đây:
select product_id, product_category_name, product_name_lenght, CUME_DIST() OVER (
PARTITION BY product_category_name
ORDER by product_name_lenght
),
PERCENT_RANK() OVER (
PARTITION BY product_category_name
ORDER by product_name_lenght
)
from "brazilian-ecommerce".olist_products_dataset;Kết quả
NTILE
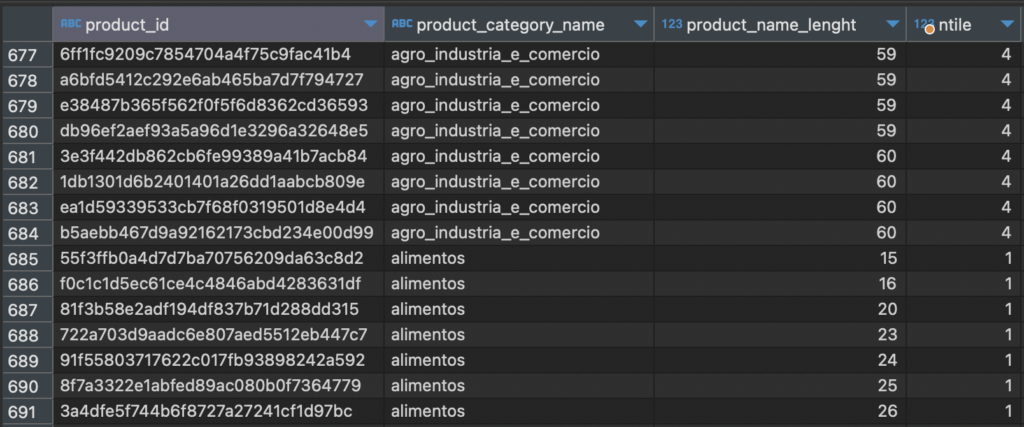
Từ khoá NTILE giúp chúng ta có thể phân nhóm trong Window Functions thành các nhóm có số lượng bằng nhau nhất có thể. Vì có thể có số lẻ trong việc phân nhóm nên việc không nhất thiết từ khóa sẽ phân nhóm đồng đều nhau.
select product_id, product_category_name, product_name_lenght, NTILE(4) OVER (
PARTITION BY product_category_name
ORDER by product_name_lenght
)
-- NTILE(4) means we want to bucket the data to four equally groups
from "brazilian-ecommerce".olist_products_dataset;Kết quả
NTH_VALUE
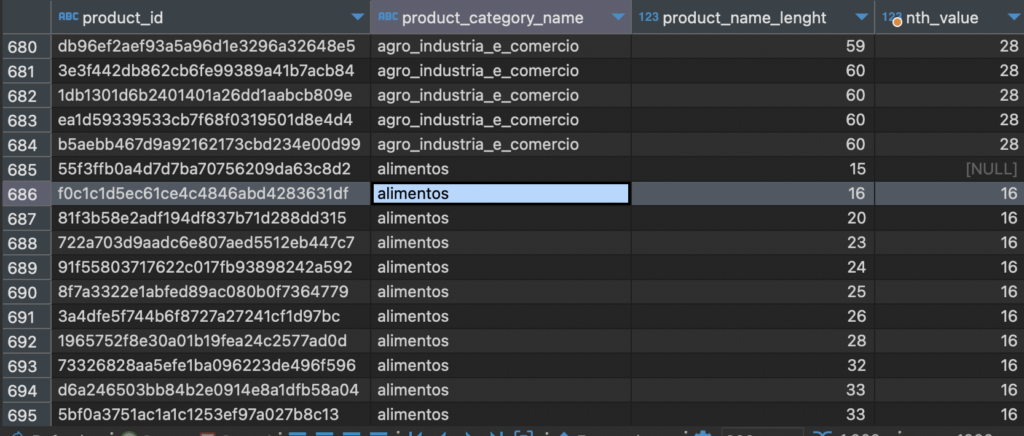
Từ khoá NTH_VALUE giúp chúng ta lấy kết quả trên một cột ở một dòng chỉ định. Ví dụ trong phân nhóm A có 04 dòng dữ liệu, chúng ta muốn lấy cột A1 ở dòng thứ thứ hai trong 04 dòng dữ liệu đó thì NTH_VALUE(A1,2) sẽ giúp chúng ta làm chuyện đó.
select product_id, product_category_name, product_name_lenght, NTH_VALUE(product_name_lenght, 2) OVER (
PARTITION BY product_category_name
ORDER by product_name_lenght
)
from "brazilian-ecommerce".olist_products_dataset;Kết quả
Tổng kết
Qua bài này, chúng ta đã học thêm 03 từ khoá CUME_DIST, NTILE và NTH_VALUE trong Window Functions trong Postgreql. Đồng thời đây là bài kết thúc phần Window Functions trong chuỗi bài SQL trong Data Analysis. Hy vọng qua nhóm bài này các bạn đã có những công cụ trong tay giúp xây dựng dữ liệu mang tính chất phức tạp hơn một chút, giúp giải quyết các vấn đề báo cáo hàng ngày.
Ở bài tiếp theo, chúng ta sẽ đi qua nhóm CTE (Common Table Expressions) trước khi các bạn có thể chính thức đi vào phần chuyên sâu hơn. Hy vọng các bạn có thể tiếp tục theo dõi các bài tiếp theo.
Xin cám ơn.


{kind=link}