
Sơ lược về Simple Linear Regression
Giới thiệu
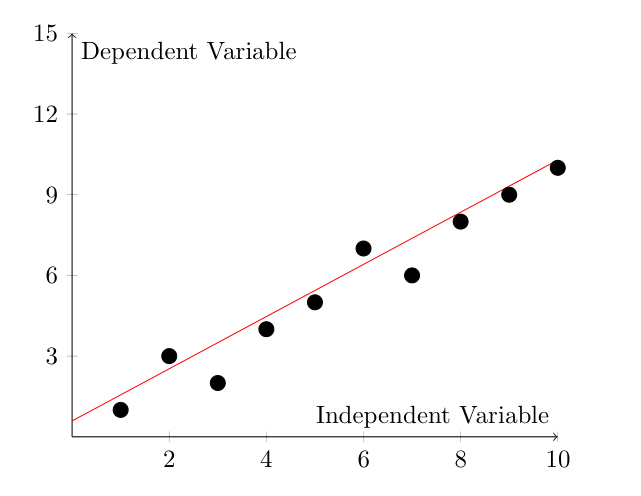
Mô hình hồi quy đơn biến (Simple Linear Regression Model) là dạng đơn giản nhất của mô hình hồi quy tuyến tính với chỉ một biến độc lập (Dependent Variable) và một biến phụ thuộc (Independent Varible), thường có dạng:
\(Y = B_0 + B_1X + u\)
Trong đó:
- Y: là biến phụ thuộc (hay biến cần được giải thích).
- X: là biến độc lập (hay biến dùng để giải thích).
- B0: là hệ số chặn (Intercept), thể hiện cho mức trung bình nếu không có bất cứ sự tác động nào từ biến độc lập.
- B1: là hệ số góc (Slope), thể hiện mức độ mà biến phụ thuộc Y sẽ bị thay đổi khi biến độc lập X thay đổi.
- u: là sai số ngẫu nhiên (Error). Được sử dụng để thay thế cho những biến số xảy ra trong mô hình mà không thể được giải thích bằng biến độc lập X.
Ưu điểm và nhược điểm
Ưu điểm
- Đơn giản dễ hiểu.
- Vì mô hình chỉ có hai biến do đó đơn giản trong việc triển khai, cũng như trực quan hóa các điểm dữ liệu chỉ bằng với Excel.
- Dễ dàng để mô tả mối quan hệ giữa biến độc lập và biến phụ thuộc.
Nhược điểm
- Do mô hình hồi quy đơn biến chỉ giới hạn mối quan hệ giữa biến phụ thuộc và biến độc lập là tuyến tính, nên đối với các quan hệ phi tuyến tính thì mô hình hồi quy đơn biến không thể biểu diễn mối quan hệ này.
- Mô hình hồi quy đơn biến cũng dễ bị ảnh hưởng nếu gặp các giá trị ngoại lai (outliers) và điều này có thể gây ra ảnh hưởng lớn trong quá trình dự đoán đường hồi quy.
- Trong thực tế các vấn đề thường khó có thể được giải thích hoàn toàn nếu chỉ dựa trên một yếu tố. Giả sử bạn muốn phân tích điều gì tác động tới chi tiêu của người tiêu dùng. Nếu chỉ sử dụng hồi quy đơn biến, chẳng hạn nếu chỉ xem xét mối quan hệ giữa chi tiêu và thu nhập thì bạn đang bỏ qua các yếu tố quan trọng (chẳng hạn như: giới tính, trình độ học vấn, kinh nghiệm,…) sẽ góp phần giải thích cho sự thay đổi về sự chi tiêu của người tiêu dùng.
- Ngoài ra còn một vấn đề khác liên quan đến độ thiên lệch đặc trưng (Specification Bias) khi một bộ dữ liệu được thu thập với nhiều biến độc lập, nhưng chỉ dùng một biến trong đó để triển khai mô hình hồi quy tuyến tính đơn biến mà bỏ qua những biến độc lập quan trọng khác cũng có tác động đến biến phụ thuộc. Điều này có thể dẫn đến hệ số tác động của biến được sử dụng trong mô hình bị chênh lệch so với tác động thực sự của biến đó và gây sai sót cho việc dự đoán (tham khảo vấn đề này trong sách Basic Econometrics – Chapter 7).
Do đó, để có một bức tranh đầy đủ hơn về mối quan hệ giữa các biến, bạn cần sử dụng mô hình hồi đa biến (Multiple Linear Regression) thay vì chỉ dựa vào phương pháp hồi quy đơn biến.
Đánh giá mô hình hồi quy
Sau khi ước tính xong các hệ số hồi quy phù hợp cho mô hình thì hệ số xác định (coefficient of determination) sẽ được sử dụng để đánh giá bao nhiêu % độ biến thiên của biến phụ thuộc Y được giải thích bởi các biến độc lập X.
Trong đó:
\(R^2 = \frac{ESS}{TSS} = 1 – \frac{RSS}{TSS}\)
- ESS: tổng bình phương giải thích (Explained Sum of Squares), là bình phương độ chênh lệch giữa từng điểm dữ liệu được dự đoán bởi mô hình hồi quy so với trung bình mẫu của chúng.
- TSS : tổng bình phương toàn phần (Total Sum of Squares), là bình phương độ chênh lệch giữa từng điểm dữ liệu thực tế so với trung bình mẫu của chúng.
- ESS: tổng bình phương phần dư (Residual Sum of Squares), là độ chênh lệch giữa ESS và TSS.
Như vậy kết quả của hệ số xác định càng tiến gần về 1 thì hàm ý các giá trị Y được dự đoán từ biến độc lập X trong mô hình hồi quy càng gần với các giá trị Y được quan sát từ bộ dữ liệu. Và ngược lại, khi hệ số này tiến về 0 thì Y dự đoán chênh lệch rất lớn với Y được quan sất từ bộ dữ liệu. Vì vậy, hiệu suất của mô hình hồi quy có thể được căn cứ thông qua kết quả của .
Sử dụng hồi quy tuyến tính trong Sklearn
Bộ dữ liệu
Dữ liệu sử dụng để dự đoán sẽ được lấy trong Kaggle trong Playground Series – Season 3, Episode 8 (https://www.kaggle.com/competitions/playground-series-s3e8/data )
Bộ dữ liệu này được sử dụng cho mục tiêu về dự đoán về giá đá quý từ những thông tin được bao gồm bên trong như là:
- carat: Trọng lượng của viên kim cương.
- cut: Chất lượng cắt của viên kim cương.
- color: Màu sắc của viên kim cương.
- clarity: Độ trong suốt của viên kim cương.
- depth: Chiều sâu của viên kim cương là khoảng cách từ đỉnh của viên kim cương xuống đến đáy của viên kim cương.
- table: Chiều rộng của đỉnh viên kim cương so với điểm đặt ngang của viên kim cương.
- x, y, z: Kích thước của viên kim cương theo độ dài, độ rộng và độ sâu.
- price: Giá trị của viên kim cương cần dự đoán.
Ngoài ra, bộ dữ liệu này cũng đã bao gồm sẵn các tập train, và test.
Thư viện Sklearn
Giới thiệu
Scikit-learn (hay sklearn) là một thư viện mã nguồn mở trong ngôn ngữ lập trình Python, cung cấp các công cụ và thuật toán trong lĩnh vực học máy (machine learning). Đây là một thư viện rất dễ cài đặt cũng như sử dụng khi nó bao gồm rất nhiều công cụ liên quan đến xử lý dữ liệu, các mô hình học máy khác nhau, hoặc đánh giá hiệu suất mô hình, …
Để cài đặt thư viện Sklearn có thể dùng command sau:
pip install -U scikit-learnClass LinearRegression
Đây là một class có sẵn trong thư viện Sklearn để triển khai mô hình hồi quy tuyến tính. Bạn có thể dễ dàng gọi class này với code:
from sklearn.linear_model import LinearRegression Đánh giá hiệu suất mô hình trong Sklearn
Mean Squared Error (MSE)
Chỉ số này thường được dùng để đánh giá hiệu suất của mô hình trong machine learning thông qua việc đánh giá độ chính xác giữa kết quả mà mô hình dự đoán so với các giá trị thực tế.
Công thức toán học của MSE có dạng:
\(MSE = \frac{1}{n} \sum_{i=1}^n (y_{true,i} – y_{pred,i})^2\)
Trong đó:
- y_true : là giá trị của biến phụ thuộc trong tập dữ liệu (tức giá trị thực tế)
- y_pred: là giá trị được dự đoán bởi mô hình thông qua các biến độc lập (tức giá trị ước tính)
Trong Sklearn, bạn có thể gọi hàm này từ module sklearn.metrics bằng code sau:
from sklearn.metrics import mean_squared_error
mse = mean_squared_error(y_true, y_pred)Root Mean Squared Error (RMSE)
Công thức toán học của RMSE có dạng:
\(RMSE = \sqrt{\frac{1}{n} \sum_{i=1}^{n} (y_{true,i} – y_{pred,i})^2}\)
Trong đó:
- y_true : là giá trị của biến phụ thuộc trong tập dữ liệu (tức giá trị thực tế)
- y_pred: là giá trị được dự đoán bởi mô hình thông qua các biến độc lập (tức giá trị ước tính)
Trong Sklearn thì không có hàm gọi trực tiếp RMSE, nhưng vì RMSE là căn bậc hai của MSE do đó có thể tính toán đơn giản bằng việc căn bậc hai của MSE như code sau:
from sklearn.metrics import mean_squared_error
rmse = np.sqrt(mean_squared_error(y_true, y_pred))Đánh giá MSE và RMSE
Mặc dù khi cả hai MSE và RMSE đều mang giá trị càng nhỏ thì mô hình có hiệu suất càng tốt. Tuy nhiên, RMSE dựa trên việc căn bậc hai trị tuyệt đối của MSE, do đó đơn vị (thứ nguyên) của giá trị dự đoán cũng sẽ bằng với đơn vị của giá trị thực tế, điều này có thể giúp người xem dễ dàng đánh giá hiệu suất của mô hình khi xem kết quả của RMSE. Nên trong thực tế RMSE thường được sử dụng hơn MSE.
Triển khai mô hình hồi quy đơn biến trong Sklearn
Bước 1: Chuẩn bị các thư viện cần
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_errorBước 2: Load tập train và tập test
df_train = pd.read_csv("train.csv")
df_test = pd.read_csv("test.csv")Dữ liệu được sử dụng trong bài này được lấy từ Kaggle, trong đó cả tập train và test này đều có sẵn trong dataset của bộ dữ liệu do đó bạn sẽ không cần thiết để tách chúng ra.
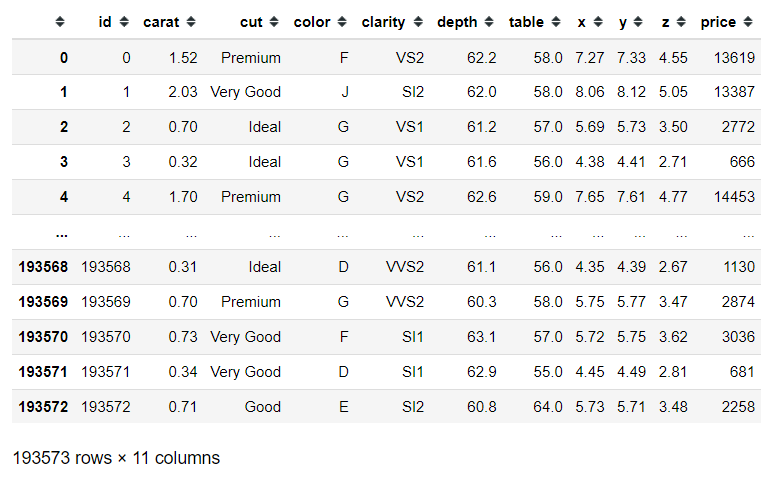
Có thể thấy trong tập train, dữ liệu sẽ bao gồm các biến độc lập là carat, cut, color, clarity, depth, table, x, y, và z. Bộ dữ liệu cũng có một biến phụ thuộc là price.
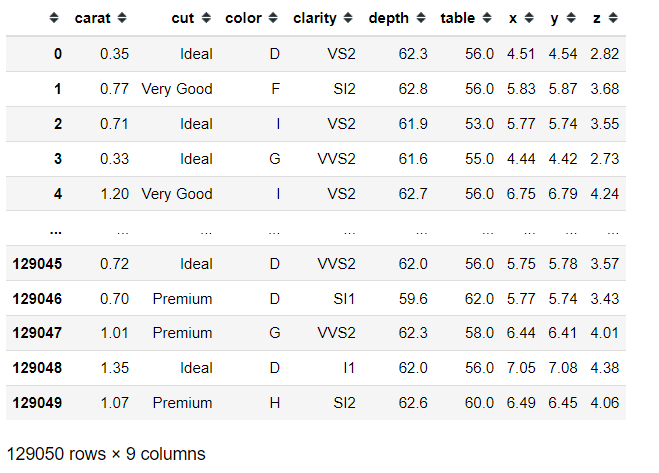
Tập test cũng sẽ có các biến độc lập tương tự nhưng sẽ không có biến phụ thuộc price. Vì khi mô hình được huấn luyện (training) xong bạn sẽ phải dùng các biến trong tập test này để dự đoán lại biến phụ thuộc price.
Chú ý:
- Thông thường một bộ dữ liệu sẽ không có sẵn tập train (dùng cho việc huấn luyện mô hình) và test (dùng cho việc kiểm tra hiệu suất mô hình).
- Ngoài ra, sau khi load dữ liệu bạn sẽ phải cần làm các bước như là “khám phá dữ liệu” (Exploratory Data Analysis), xử lý dữ liệu (Data processing), và nhiều bước khác để giúp dữ liệu trở tốt hơn nhằm tăng độ chính xác của mô hình được huấn luyện, rồi sau đó mới cần tách ra tập train và test.
- Tuy nhiên, ở bài này chúng ta sẽ chỉ làm quen với việc sử dụng sklearn để triển khai một mô hình hồi quy tuyến tính đơn biến đơn giản. Do đó, bạn có thể tạm bỏ qua những bước xử lý như đã đề cập.
Bước 3: Chỉ định biến sẽ dùng cho mô hình hồi quy đơn biến
X_train = df_train.carat
y_train = df_train.priceỞ đoạn code trên, bạn sẽ sử dụng cột carat trong tập train làm biến độc lập X_train và biến này sẽ được dùng để giải thích biến phụ thuộc. Cột price trong tập train sẽ được đóng vai trò như biến phụ thuộc y_train.
Chú ý: Có thể cho vào biến X_train nhiều hơn một biến phụ thuộc. Nhưng vì bài này chỉ liên quan đến mô hình hồi quy đơn biến, cho đó chúng ta chỉ sử dụng một biến là carat cho biến phụ thuộc này.
Bước 4: Tiến hành huấn luyện mô hình hồi quy tuyến tính đơn biến
lr = LinearRegression()
lr.fit(X_train, y_train)Ở bước này, bạn sẽ khởi tạo một mô hình hồi quy tuyến tính và lưu vào biến lr. Sau đó, chúng ta sẽ dùng hàm .fit với đối số thứ nhất là biến độc lập, và đối số thứ hai là biến phụ thuộc để bắt đầu quá trình huấn luyện nhằm tìm ra mô hình tối ưu nhất cho dữ liệu được đưa vào.
Các giá trị sau khi huấn luyện xong sẽ được lưu lại trong biến lr.
Chú ý: nếu có lỗi xảy ra liên quan đến hình dạng (shape) của biến độc lập X_train, thì bạn có thể quay về bước 3 và chỉnh X_train thành:
X_train = np.array(df_train.carat).reshape(-1, 1)Bước 5: Dự đoán giá trị cho tập test
Sử dụng đoạn code này:
y_predict=lr.predict(df_test.carat)Hoặc code này trong trường hợp xảy ra lỗi về hình dạng của biến độc lập trong tập test:
y_predict=lr.predict(np.array(df_test.carat).reshape(-1,1))Trong đoạn code này, bạn sẽ dùng .predict nhằm sử dụng mô hình đã được huấn luyện ở bước 4 với đầu vào là biến độc lập carat ở trong tập test để dự đoán ra biến phụ thuộc price vốn không có trong tập test này.

Bước 6: Kiểm định hiệu suất mô hình
Cách 1: Dùng Kaggle để kiểm định
Vì đây là dữ liệu trong một cuộc thi của Kaggle tổ chức nên bạn có thể gửi file đã dự đoán vào cuộc thi đó trong Kaggle nhằm lấy đánh giá về hiệu suất mô hình.

Kết quả cho thấy là giữa kết quả dự đoán từ mô hình và giá trị thực tế có một khoảng chênh lệch khá lớn và từ đó bạn nên tìm cách cải thiện mô hình (như xử lý tốt dữ liệu, thêm nhiều biến phụ thuộc mới, …) để giảm giá trị này xuống.
Cách 2: Dùng mean_squared_error trong thư viện sklearn để kiểm định
Như đã giải thích trong phần chú ý ở bước 1, thông thường bạn sẽ phải tự tạo một tập test chứa các biến phụ thuộc và biến độc lập tương tự tập train từ bộ dữ liệu gốc để dùng cho việc kiểm định hiệu suất mô hình bằng mean_squared_error trong sklearn.
Tuy nhiên, tập dữ liệu này vì dùng cho cuộc thi trong Kaggle do đó tập test sẽ không có biến phụ thuộc Y để các nhân đánh giá. Do đó, tạm thời chúng ta sẽ dùng chính biến độc lập X_train của tập train để dự đoán lại chính biến phụ thuộc này:
y_predict_train =lr.predict(X_train)
rmse = np.sqrt(mean_squared_error(df_train.price, y_predict_train))Như trên, bạn sẽ dùng chính X_train đã dùng để đào tạo mô hình trước đó để dự đoán biến phụ thuộc y_predict_train. Sau đó, bạn sẽ dùng hàm mean_squared_error với đối số đầu là biến phụ thuộc price gốc (có sẵn trong bộ dữ liệu) và biến phụ thuộc price vừa dự đoán để cho ra MSE.
Như đã biết, thì RMSE được tính dựa trên căn bậc hai của MSE, do đó bạn triển khai một hàm sqrt để căn bậc hai giá trị MSE và kết quả thu được sẽ là RMSE của dữ liệu.

Có thể thấy kết quả kiểm định cũng tương tự như khi kiểm định trong Kaggle
Chú ý: Thực tế thì bạn không nên dùng chính tập train để dự đoán, vì mô hình hồi quy tuyến tính được huấn luyện sao cho phù hợp nhất với bộ dữ liệu đào tạo, do đó nếu dùng chính bộ dữ liệu này để kiểm tra hiệu suất mô hình thì kết quả sẽ rất tốt, nhưng khi kiểm tra trên tập test thì kết quả lại rất kém.
Tổng kết Simple Linear Regression
Trong bài này bạn đã hiểu được những kiến thức căn bản về hồi quy đơn biến, cách triển khai mô hình hồi quy đơn biến trong Sklearn, cũng như kiểm định hiệu suất của mô hình nhằm đánh giá được độ tốt của mô hình sau khi huấn luyện xong. Ở bài sau chúng ta sẽ tiếp tục tìm hiểu về cách triển khai mô hình hồi quy đa biến (Multiple Linear Regression) bằng Sklearn.


{kind=link}