
Chào các bạn đã quay lại chuỗi bài xử lý dữ liệu tracking bằng việc sử dụng Vertx.io lập trình đầu HTTP thu thập dữ liệu. Ở phần này chúng ta sẽ đi sâu hơn về việc sử dụng Redis sao cho hiệu quả và cách sắp xếp lưu trữ files dữ liệu hợp lý.
Tìm hiểu vấn đề
Ở bài trước chúng ta sử dụng đoạn code sau để lưu dữ liệu vào Redis và lưu vào files:
private void sumToRedis(Date receiveTime, JsonObject row) {
boolean isSuccess = row.getString("result").equals("success");
String hKey = hDF.format(receiveTime);
if(isSuccess) {
this.redisAPI.hincrby(hKey, "success_device:" + row.getString("device"), "1");
this.redisAPI.hincrby(hKey, "success_browser:" + row.getString("browser"), "1");
this.redisAPI.hincrby(hKey, "success_time", row.getInteger("duration") + "");
if(row.getString("accountId") != null)
this.redisAPI.hincrby(hKey, "success_reg_user", "1");
} else {
this.redisAPI.hincrby(hKey, "error_device:" + row.getString("device"), "1");
this.redisAPI.hincrby(hKey, "error_browser:" + row.getString("browser"), "1");
this.redisAPI.hincrby(hKey, "error_time", row.getInteger("duration") + "");
this.redisAPI.hincrby(hKey, "error_cause", row.getString("message"));
if(row.getString("accountId") != null)
this.redisAPI.hincrby(hKey, "error_reg_user", "1");
}
}
//Since FileSystem instance need to be created from Vertx instance, we have to put in method
private void writeLog(Vertx vertx, Date receiveTime, JsonObject row) {
FileSystem fs = vertx.fileSystem();
StringBuilder sb = new StringBuilder();
sb.append(row.getString("device")).append("\t");
sb.append(row.getString("browser")).append("\t");
sb.append(row.getString("result")).append("\t");
sb.append(row.getString("message")).append("\t");
sb.append(row.getInteger("duration")).append("\t");
sb.append(row.getString("accountId", ""));
fs.writeFile(fileDF.format(receiveTime), Buffer.buffer(sb.toString()));
}Sẽ có 02 vấn đề:
- Số lượng requests gửi về Redis tương ứng với số lượng IO operation của Redis.
- Files lưu trữ không theo quy tắc, về lâu dài. Số lượng files phát sinh nhiều sẽ gây chậm việc xử lý (như liệt kê file “ls” hay lấy một khoảng thời gian nhất định nào đó).
Xử lý vấn đề
Vấn đề Redis
Để hình dung được vấn đề, bạn sẽ cần đo lường một chút về tốc độ hiện tại khi đẩy dữ liệu về Redis. Nếu bạn sử dụng Redis trên nền Docker thì có thể sử dụng các đoạn lệnh sau để tiến hành truy cập vào container của Redis.
Dùng lệnh của docker để liệt kê các containers đang chạy:
docker psTìm và copy Container ID của Redis, ví dụ e3ed666c1234 là Id của Redis Container.

Sau đó sử dụng đoạn lệnh sau để có thể đăng nhập vào container.
docker exec -ti <Redis Container ID> bashSau đó bạn tiếp tục sử dụng lệnh:
redis-cliSử dụng câu lệnh sau:
monitorKhi thành công, mà hình của bạn sẽ hiển thị kết quả như sau:

Chúng ta sẽ bắt đầu monitor thử việc gọi đẩy dữ liệu với cách code hiện tại nhé. Gọi lần nữa bằng Postman hoặc lệnh curl:
curl --location --request POST 'http://localhost:8080/accept_tracking' \
--header 'Content-Type: application/json' \
--data-raw '{
"device": "mobile",
"browser": "Chrome",
"result": "success",
"message": "OK",
"duration": 3432,
"accountId": null
}'Bạn xem kết quả bạn nhận được từ màn hình monitor sẽ tương đương như thế này.
1675092035.393848 [0 172.17.0.1:63890] "hincrby" "2023-01-30-22" "success_device:mobile" "1"
1675092035.393916 [0 172.17.0.1:63890] "hincrby" "2023-01-30-22" "success_browser:Chrome" "1"
1675092035.393969 [0 172.17.0.1:63890] "hincrby" "2023-01-30-22" "success_time" "3432"
1675092062.379798 [0 172.17.0.1:63890] "hincrby" "2023-01-30-22" "success_device:mobile" "1"
1675092062.379847 [0 172.17.0.1:63890] "hincrby" "2023-01-30-22" "success_browser:Chrome" "1"
1675092062.379884 [0 172.17.0.1:63890] "hincrby" "2023-01-30-22" "success_time" "3432"Bạn nhận thấy rằng, trung bình thời gian xử lý 03 câu lệnh hincrby sẽ khoản 1 ms (1000 ns), bỏ qua những khi CPU bị spike. Sẽ là không vấn đề gì khi số lượng requests chúng ta gửi tới Redis là thấp. Tuy nhiên nếu là 1000 requests trong cùng thời điểm thì tổng lượng thời gian cần thiết để hoàn thành ở Redis là 1000 ms (1s).
Để khắc phục chuyện đó, chúng ta có thể sử dụng kỹ thuật pipelining ở Redis để gửi một bó các câu lệnh vào Redis. Trong bài viết, đội ngũ phát triển có đề cập tốc độ đo lường giữa việc xài pipelining và không xài như sau:

Để chuyển đổi sang sử dụng pipelining trong Vertx.io, chúng ta sẽ cần sửa đổi lại code như sau:
- Chuyển qua sử dụng RedisConnection thay vì interface RedisAPI.
- Đưa các lệnh hincrby vào danh sách (ArrayList) để gửi bó lệnh đi.
//We change to use RedisConnection instead of RedisAPI
//RedisAPI redisAPI = null;
//public void setRedisAPI(RedisAPI redisAPI) { this.redisAPI = redisAPI; }
RedisConnection redisConn = null;
public void setRedisConn(RedisConnection redisConn) {
this.redisConn = redisConn;
}
...
private void sumToRedis(Date receiveTime, JsonObject row) {
boolean isSuccess = row.getString("result").equals("success");
String hKey = hDF.format(receiveTime);
List<Request> requests = new ArrayList<>();
if (isSuccess) {
requests.add(Request.cmd(Command.HINCRBY, hKey, "success_device:" + row.getString("device"), 1));
requests.add(Request.cmd(Command.HINCRBY, hKey, "success_browser:" + row.getString("browser"), 1));
requests.add(Request.cmd(Command.HINCRBY, hKey, "success_time", row.getInteger("duration")));
if (row.getString("accountId") != null)
requests.add(Request.cmd(Command.HINCRBY, hKey, "success_reg_user", 1));
} else {
requests.add(Request.cmd(Command.HINCRBY, hKey, "error_device:" + row.getString("device"), 1));
requests.add(Request.cmd(Command.HINCRBY, hKey, "error_browser:" + row.getString("browser"), 1));
requests.add(Request.cmd(Command.HINCRBY, hKey, "error_time", row.getInteger("duration")));
requests.add(Request.cmd(Command.HINCRBY, hKey, "error_cause:" + row.getString("message"), 1));
if (row.getString("accountId") != null)
requests.add(Request.cmd(Command.HINCRBY, hKey, "error_reg_user", 1));
}
this.redisConn.batch(requests);
}
...
//Also change to set to RedisConnection to RedisAPI here
public static void main(String[] args) {
...
connect.onSuccess(res -> {
//handlerObj.setRedisAPI(RedisAPI.api(res));
handlerObj.setRedisConn(res);
...
});
} Sau khi sửa code, chúng ta cho chạy lần nữa đầu HTTP và gửi dữ liệu test lại nhé. Khi gửi xong chúng ta xem lại trong Redis monitor để xem tốc độ lần này thế nào.
1675092173.552904 [0 172.17.0.1:63892] "hincrby" "2023-01-30-22" "success_device:mobile" "1"
1675092173.553424 [0 172.17.0.1:63892] "hincrby" "2023-01-30-22" "success_browser:Chrome" "1"
1675092173.565659 [0 172.17.0.1:63892] "hincrby" "2023-01-30-22" "success_time" "3432"
1675092204.791874 [0 172.17.0.1:63892] "hincrby" "2023-01-30-22" "success_device:mobile" "1"
1675092204.791916 [0 172.17.0.1:63892] "hincrby" "2023-01-30-22" "success_browser:Chrome" "1"
1675092204.792150 [0 172.17.0.1:63892] "hincrby" "2023-01-30-22" "success_time" "3432"Các câu lệnh bây giờ chỉ dao động ở ~200ns (0.2ms). Như vậy tốc độ đã được đẩy nhanh hơn khoản 4-5 lần. Như trong bài viết đã đề cập:
As you can see, using pipelining, we improved the transfer by a factor of five.
Vấn đề lưu trữ
Như đã đề cập, các log files chúng ta lưu trữ đều nằm ngay tại chỗ chương trình đang chạy. Chúng ta cũng có thể lưu files vào một directory khác, như logs chẳng hạn. Nhưng về lâu dài cách lưu trữ trên sẽ khiến chúng ta rất khó truy cập vào directory đó: ví dụ bạn lưu files mỗi 15 phút/lần, vậy trong 01 năm sẽ tương đương: 24 * 4 * 356 = 34176 files.
Với 34176 files có thể vẫn chưa phải vấn đề lớn, nhưng chúng ta là Data Engineering, chúng ta phải đảm bảo chính xác mỗi yếu tố của sản phẩm chúng ta tạo ra hoạt động đúng và đảm bảo tốc độ hợp lý. Bằng cách chúng luôn tính toán các thành phần trong sản phẩm có sự phát triển về không gian theo thời gian trôi qua (ví dụ: data ngày càng phình to theo số tháng, số năm).
Đồng thời khi lưu logs files, chúng ta sẽ có khả năng sẽ cần tái sử dụng lại theo một khung thời gian nhất định hoặc toàn bộ (với trường hợp cần sửa đổi lại cách thức tính toán mới chẳng hạn). Vậy chúng ta sẽ lưu trữ theo thời gian.
Ngoài ra chúng cũng sẽ cần lưu ý yếu tố mở rộng. Hiện tại trong đề bài, chúng ta chỉ mởi tracking sự kiện khách hàng đăng ký form. Tuy nhiên nếu bạn chỉ dừng ở đó thì cơ hội cao là chúng ta sẽ bị layoffs đấy. Vì khi các bạn tạo ra một sản phẩm tốt, người dùng sẽ liên tục yêu cầu bạn làm thêm những tính năng khác (đây là một trong những metrics quan trọng đo lường sản phẩm thành công hay không).
Tóm lại, chúng ta sẽ xây dựng lại cấu trúc logs files như sau:
[parrent_directory]/<data_object>/year=yyyy/month=MM/day=dd/hour=HH
Chúng ta sẽ update code lại như sau:
private void writeLog(Vertx vertx, Date receiveTime, JsonObject row) {
FileSystem fs = vertx.fileSystem();
StringBuilder sb = new StringBuilder();
sb.append(row.getString("device")).append("\t");
sb.append(row.getString("browser")).append("\t");
sb.append(row.getString("result")).append("\t");
sb.append(row.getString("message")).append("\t");
sb.append(row.getInteger("duration")).append("\t");
sb.append(row.getString("accountId", ""));
String fileName = fileDF.format(receiveTime);
//Because log files are writting to directories now, so we have to create it whenever file is not created yet
if(!fs.existsBlocking(fileName)) {
fs.mkdirsBlocking(fileName.substring(0, fileName.lastIndexOf("/")));
fs.createFileBlocking(fileName);
}
fs.writeFile(fileName, Buffer.buffer(sb.toString()));
}Chạy thử và chúng ta sẽ thấy logs được lưu như sau:
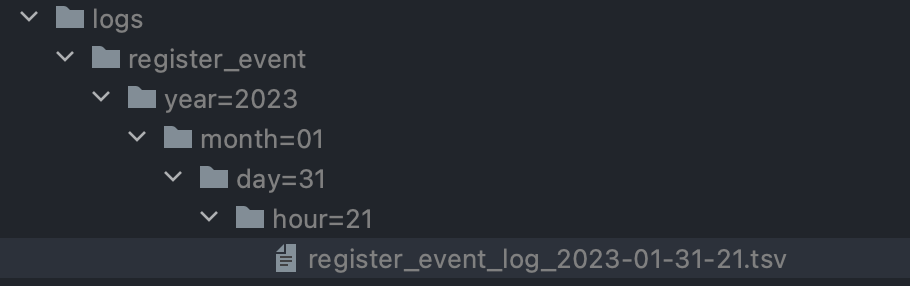
Fact:
- đây cũng là cách thức lưu trữ files trên S3 của Amazon Web Services, Cloud Storage của Google Cloud.
- Cách thức lưu files như trên vẫn chưa thực sự tối ưu, vì mỗi request sẽ ghi vào 01 dòng. Nếu bạn nhận 5k requests/giây thì tương đương phải write liên tục 5k dòng. Chúng ta sẽ xử lý vấn đề này bằng một bài viết khác nhé.
Tóm tắt
Chúng ta đã biết thêm về:
- cách tối ưu hoá tốc độ xử lý request trên Redis.
- cách sắp xếp lưu trữ data files thuận tiện cho việc lưu trữ và tái sử dụng.
- hiểu thêm một chút về công việc của Data Engineer, đồng thời tính chính xác lẫn khả năng tính toán các yếu tố ảnh hưởng tới sản phẩm.
Các bạn có thể trực tiếp lấy git source của bài viết ở đây Github. Ở bài tiếp theo, chúng ta sẽ quay lại trục bài chính, lần này chúng ta sẽ tiếp xúc với cơ sở dữ liệu: PostgreSQL – một trong những cơ sở dữ liệu được ưa dùng nhất cho việc thống kê dữ liệu.
Hẹn gặp lại bạn ở bài tiếp theo.


{kind=link}